
آشنایی با خانواده الگوریتم YOLO

تشخیص اشیا یکی از مهمترین موضوعات در بینایی کامپیوتر است. اکثر مشکلات بینایی کامپیوتر، شامل تشخیص دستهبندی اشیاء مانند عابران پیاده، اتومبیلها، اتوبوسها، چهرهها و غیره است. این یکی از زمینههایی است که فقط به دانشگاه محدود نمیشود، بلکه دارای یک مورد بالقوه استفاده تجاری در دنیای واقعی در حوزههایی مانند نظارت تصویری، مراقبتهای بهداشتی، حسگر داخل خودرو و رانندگی مستقل و…
بسیاری از موارد استفاده، به ویژه رانندگی خودکار، به دقت بالا و سرعت استنتاج بلادرنگ نیاز دارند. از این رو، انتخاب یک آشکارساز شی که در سرعت و دقت مناسب باشد، ضروری است. YOLO (You Only Look Once) یک آشکارساز شی تک مرحله ای است که برای دستیابی به هر دو هدف (یعنی سرعت و دقت) معرفی شده است. و امروز، با پوشش همه انواع YOLO (به عنوان مثال، YOLOv1، YOLOv2،…، YOLOX، YOLOR) به معرفی خانواده YOLO خواهیم پرداخت.
از زمان آغاز به کار، زمینه تشخیص اشیا به طور قابل توجهی رشد کرده است، و معماری های پیشرفته به خوبی در مجموعه داده های آزمایشی مختلف تعمیم می یابند. اما برای درک جادوی پشت این بهترین معماریهای کنونی، لازم است بدانیم همه چیز چگونه شروع شد و تا کجا در خانواده YOLO رسیدهایم.
سه دسته از الگوریتم ها در تشخیص اشیا وجود دارد:
- ✅ بر اساس دید سنتی کامپیوتر
- ✅ الگوریتم های مبتنی بر یادگیری عمیق دو مرحله ای
- ✅ سوم الگوریتم های مبتنی بر یادگیری عمیق تک مرحله ای است
و امروز، ما میخواهیم خانواده تشخیص شی YOLO را که تحت الگوریتمهای یادگیری عمیق تک مرحلهای قرار میگیرد، بررسی کنیم.
ما معتقدیم که این یک مقاله منحصر به فردی است که همه انواع YOLO را در یک پست پوشش می دهد و به شما کمک می کند تا بینشی عالی در مورد هر گونه داشته باشید و ممکن است به شما کمک کند بهترین نسخه YOLO را برای پروژه خود انتخاب کنید.
مقدمه ای بر تشخیص اشیا
به یاد بیاورید که در طبقه بندی تصویر(Image classification)، هدف پاسخ به این سوال است که “چه چیزی در تصویر وجود دارد؟” که در آن مدل سعی می کند با اختصاص دادن یک برچسب خاص به تصویر، کل تصویر را درک کند.
به طور کلی، ما با سناریوهایی سر و کار داریم که در آن تنها یک شی در طبقه بندی تصویر وجود دارد. همانطور که در شکل 1 نشان داده شده است ، ما یک بابانوئل و چند شی دیگر داریم، اما شی اصلی بابانوئل است که به درستی با احتمال 98٪ طبقه بندی شده است. عالیه. در موارد خاصی مانند این، زمانی که یک تصویر یک شی واحد را نشان می دهد، طبقه بندی برای پاسخ به سوال ما کافی است.
 شکل 1: تصویر طبقه بندی شده به عنوان بابانوئل با دقت 98٪
شکل 1: تصویر طبقه بندی شده به عنوان بابانوئل با دقت 98٪
با این حال، سناریوهای زیادی وجود دارد که نمیتوانیم با یک برچسب بگوییم چه چیزی در تصویر وجود دارد، و طبقهبندی تصویر برای کمک به پاسخ به این سؤال کافی نیست. به عنوان مثال، شکل 2 را در نظر بگیرید ، که در آن مدل سه شی را تشخیص می دهد: دو شخص و یک دستکش بیسبال، و نه فقط این، بلکه مکان هر جسم را نیز مشخص می کند. این به عنوان تشخیص شی(Object detection) شناخته می شود.

شکل 2: نمونه هایی از تشخیص شی(Object detection) با استفاده از آشکارسازهای تک شات (SSD)
یکی دیگر از موارد استفاده حیاتی برای تشخیص اشیا، تشخیص خودکار پلاک خودرو است، همانطور که در شکل 3 نشان داده شده است.
خب حالا یک سوال؟! چگونه حروف و اعداد پلاک خودرو را تشخیص دهیم؟
خب مشخصا اول باید محل پلاک را با شی یابی شناسایی کنیم و سپس الگوریتم دوم را برای تشخیص ارقام اعمال کنیم.
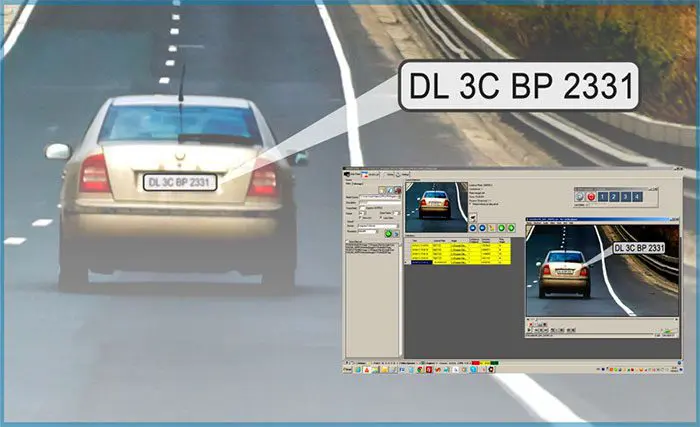
شکل 3: نمونه ای از یک سیستم تشخیص خودکار پلاک شماره در زمان واقعی (منبع: Chem on Pinterest ).
تشخیص اشیا(Object detection) شامل وظایف طبقهبندی و محلیسازی میشود و برای تحلیل موارد واقعیتر که ممکن است چندین شی در یک تصویر وجود داشته باشد، استفاده میشود. از این رو، تشخیص شی یک فرآیند دو مرحله ای است. اولین قدم یافتن مکان اشیا است.
و مرحله دوم طبقه بندی این جعبه های محدود کننده به کلاس های مختلف است زیرا این تشخیص شی از تمام مشکلات مرتبط با طبقه بندی تصویر رنج می برد. علاوه بر این، چالش های بومی سازی و سرعت اجرا را نیز دارد.
چالش ها
- سناریوی شلوغ یا به هم ریخته: تعداد زیاد اشیاء در تصویر ( شکل 4 ) آن را به شدت شلوغ می کند. این چالشهای مختلفی را برای مدل تشخیص شی ایجاد میکند، مانند انسداد میتواند بزرگ باشد، اجسام میتوانند کوچک باشند، و مقیاس ممکن است ناسازگار باشد.

شکل 4: گروه بزرگی از مردم در حال تماشای یک مسابقه در یک استادیوم ( منبع ).
- واریانس درون کلاسی: یکی دیگر از چالش های اصلی برای تشخیص اشیا، تشخیص صحیح اشیاء هم کلاس است که می توانند واریانس بالایی داشته باشند. به عنوان مثال، همانطور که در شکل 5 نشان داده شده است، شش نژاد سگ وجود دارد، و همه آنها دارای اندازه، رنگ، طول خز، گوش و غیره متفاوت هستند، بنابراین تشخیص این اشیاء از یک کلاس می تواند چالش برانگیز باشد.

شکل 5: شش نژاد سگ ( منبع ).
عدم تعادل طبقاتی: این چالشی است که تقریباً همه روشها را تحت تأثیر قرار میدهد، خواه تصویر، متن، سری زمانی. به طور خاص تر، در حوزه تصویر، طبقه بندی تصاویر بسیار مشکل است و تشخیص اشیا نیز از این قاعده مستثنی نیست. همانطور که در شکل 6 نشان داده شده است، آن را عدم تعادل کلاس پیش زمینه-پس زمینه در تشخیص شی می نامیم .
- برای درک اینکه چگونه عدم تعادل کلاس می تواند مشکلی را در تشخیص شی ایجاد کند، تصویری را در نظر بگیرید که دارای تعداد بسیار کمی از اشیاء اولیه است. باقیمانده تصویر با پس زمینه پر شده است. در نتیجه، مدل به بسیاری از مناطق در تصویر (مجموعه داده) نگاه می کند که در آن بیشتر مناطق منفی در نظر گرفته می شوند. به دلیل این موارد منفی، مدل هیچ اطلاعات مفیدی نمی آموزد و می تواند کل آموزش مدل را تحت تأثیر قرار دهد.
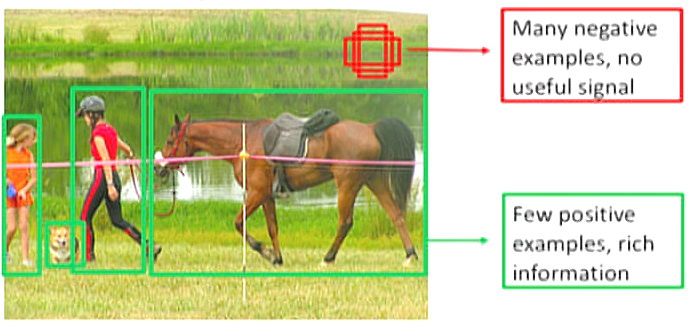
شکل 6: بسیاری از نمونه های پس زمینه منفی و چند نمونه پیش زمینه مثبت ( منبع ).
بسیاری از چالشهای دیگر مانند انسداد ، تغییر شکل ، تغییر دیدگاه ، شرایط روشنایی ، و سرعت ضروری برای تشخیص بلادرنگ (که در بسیاری از کاربردهای صنعتی مورد نیاز است) با تشخیص اشیا مرتبط هستند.
تاریخچه تشخیص اشیا
تشخیص اشیا یکی از بحرانی ترین و چالش برانگیزترین مسائل در بینایی کامپیوتری است و در دهه گذشته با توسعه خود تاریخچه ای را ایجاد کرده است. با این وجود، پیشرفت در این زمینه قابل توجه بوده است. هر سال، جامعه تحقیقاتی به معیار جدیدی دست می یابد. و البته، همه اینها بدون قدرت شبکه های عصبی عمیق و محاسبات عظیم توسط پردازنده های گرافیکی NVIDIA امکان پذیر نبود.
در تاریخ کشف اشیا، دو دوره متمایز وجود داشته است:
- رویکردهای سنتی بینایی کامپیوتری تا سال 2010 در بازی وجود داشت.
- از سال 2012، دوران جدیدی از شبکههای عصبی کانولوشنال آغاز شد که AlexNet (یک شبکه طبقهبندی تصویر) در چالش تشخیص تصویری ImageNet برنده شد .
این تمایز بین دو دوره در شکل 7 نیز مشهود است که نقشه راه تشخیص اشیا را نشان میدهد، از آشکارساز Viola-Jones در سال 2004 تا EfficientDet در سال 2019، شایان ذکر است که روشهای تشخیص مبتنی بر یادگیری عمیق بیشتر هستند. به آشکارسازهای دو مرحله ای و آشکارسازهای تک مرحله ای طبقه بندی می شوند.
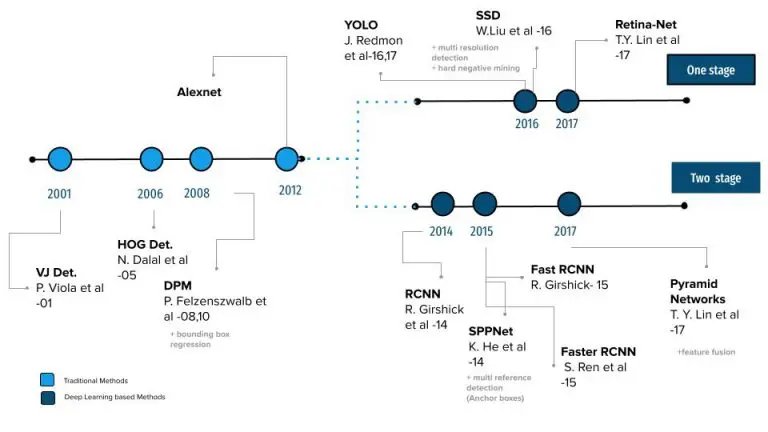
شکل 7: نقشه راه تشخیص اشیا (منبع).
اکثر الگوریتمهای سنتی تشخیص اشیا مانند Viola-Jones، Histogram of Oriented Gradients (HOG) و Model Parts Deformable Parts (DPM) بر استخراج ویژگیهای دستساز مانند لبهها، گوشهها، گرادیانها از تصویر و الگوریتمهای یادگیری ماشین کلاسیک متکی هستند. برای مثال، The Viola-Jones، اولین آشکارساز شی، فقط برای تشخیص چهرههای جلوی انسان طراحی شده بود و در صورتهای جانبی و بالا/پایین به خوبی عمل نمیکرد.
سپس، در سال 2012، دوره جدیدی آغاز شد. انقلابی که بازی را برای بینایی کامپیوتر به طور کامل تغییر داد، زمانی که AlexNet ، یک معماری شبکه عصبی پیچیده عمیق (CNN) به دلیل نیاز به بهبود نتایج چالش ImageNet متولد شد، در چالش ImageNet LSVRC-2012 در سال 2012 به دقت قابل توجهی دست یافت (دقت 84.7 درصد ) در مقایسه با نفر دوم که دقت 73.8 درصد داشت.
سپس استفاده از این معماریهای پیشرفته طبقهبندی تصویر به عنوان استخراجکننده ویژگی در خط لوله تشخیص اشیاء، زمان زیادی بود. هر دو مشکل به هم مرتبط هستند و بر یادگیری ویژگی های قوی سطح بالا متکی هستند. از این رو، گیرشیک و همکاران. (2014) نشان داد که چگونه میتوانیم از ویژگیهای کانولوشنال برای تشخیص اشیا استفاده کنیم، با معرفی R-CNN (استفاده از CNN در پیشنهادات منطقه). از آن زمان، تشخیص اشیا با سرعت بی سابقه ای شروع به تکامل کرده است.
همانطور که در شکل 7 نشان داده شده است ، روش های تشخیص یادگیری عمیق را می توان در دو مرحله گروه بندی کرد. اولین مورد، الگوریتمهای تشخیص دو مرحلهای نامیده میشود که پیشبینیهایی را در چند مرحله انجام میدهند، از جمله شبکههایی مانند RCNN، Fast-RCNN Faster-RCNN و غیره.
دسته دوم آشکارسازها، آشکارسازهای تک مرحله ای هستند مانند SSD ، YOLO، EfficientDet و غیره.
در شکل 8 ، میتوانید همه الگوریتمهای تشخیص شی YOLO و نحوه تکامل آنها را ببینید، از YOLOv1 در سال 2016 و دستیابی به 63.4 mAP در مجموعه داده پاسکال VOC (20 کلاس) تا YOLOR در سال 2021 با 73.3 mAP در MS بسیار چالشبرانگیزتر. مجموعه داده COCO (80 کلاس). و این زیبایی دانشگاه است. با سخت کوشی و انعطاف پذیری مداوم، تشخیص شی YOLO راه طولانی را پیموده است!
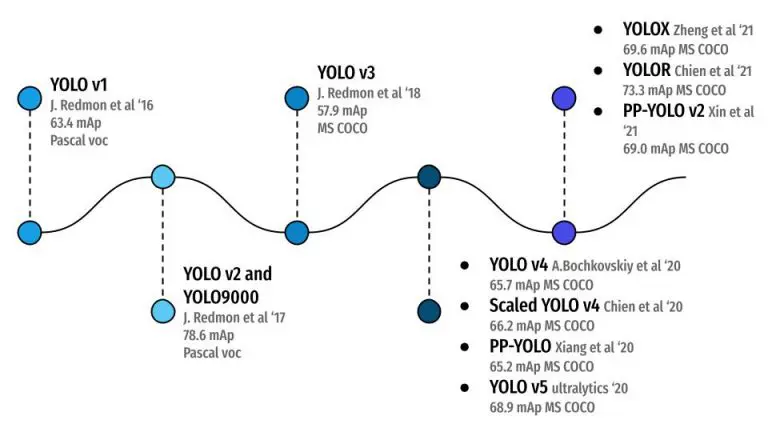
شکل 8: تاریخچه YOLO
آشکارسازهای شی تک مرحله ای چیست؟
آشکارسازهای شی تک مرحله ای، کلاسی از معماری های تشخیص اشیا هستند که یک مرحله ای اند. آنها تشخیص شی را به عنوان یک مشکل رگرسیون ساده در نظر می گیرند. برای مثال، تصویر ورودی که به شبکه داده میشود، مستقیماً احتمالات کلاس و مختصات جعبه مرزی را به خروجی میدهد.
این مدلها از مرحله پیشنهاد منطقه، که به عنوان شبکه پیشنهادی منطقه نیز شناخته میشود، میگذرند، که به طور کلی بخشی از آشکارسازهای شی دو مرحلهای است که مناطقی از تصویر هستند که میتوانند حاوی یک شی باشند.
شکل 9 گردش کار آشکارساز تک مرحله ای و دو مرحله ای را نشان می دهد. در تک مرحله ای، ما هد تشخیص را مستقیماً روی نقشه ویژگی اعمال می کنیم، در حالی که در دو مرحله، ابتدا یک شبکه پیشنهادی منطقه را روی نقشه های ویژگی اعمال می کنیم.
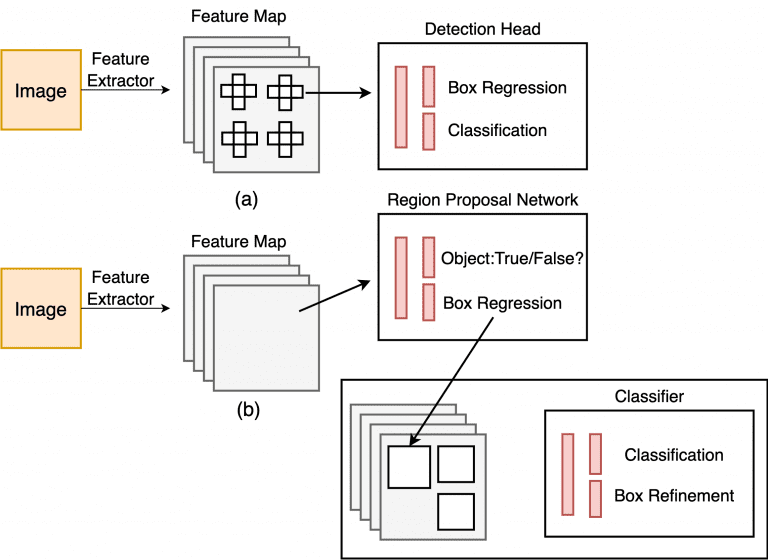
شکل 9: آشکارساز تک مرحله ای ( بالا ) و دو مرحله ای ( پایین )
سپس این مناطق به مرحله دوم منتقل می شوند و برای هر منطقه پیش بینی می کنند. Faster-RCNN و Mask-RCNN برخی از محبوب ترین آشکارسازهای شی دو مرحله ای هستند.
در حالی که آشکارسازهای دو مرحلهای دقیقتر از آشکارسازهای شی تکمرحلهای در نظر گرفته میشوند، اما سرعت استنتاج پایینتری شامل مراحل متعدد دارند. از سوی دیگر، آشکارسازهای تک مرحله ای بسیار سریعتر از آشکارسازهای دو مرحله ای هستند.
YOLOv1
در سال 2016 جوزف ردمون(joseph redmon) و همکاران. در کنفرانس CVPR اولین آشکارساز شی تک مرحله ای را با نام You Only One One Look: Unified, Real-Time Object Detection منتشر کرد.
YOLO (You Only One One Look) یک پیشرفت در زمینه تشخیص اشیا بود زیرا اولین رویکرد آشکارساز شی تک مرحله ای بود که تشخیص را به عنوان یک مشکل رگرسیون در نظر می گرفت. معماری تشخیص فقط یک بار به تصویر نگاه می کرد تا مکان اشیاء و برچسب کلاس آنها را پیش بینی کند.
بر خلاف رویکرد آشکارساز دو مرحله ای (Fast-RCNN , Faster-RCNN)، YOLOv1 دارای پروپوزال مولد و مراحل پالایش نیست. از یک شبکه عصبی منفرد استفاده می کند که احتمالات کلاس و مختصات جعبه مرزی را از کل یک تصویر در یک گذر پیش بینی می کند. می توان آن را سرتاسر بهینه کرد زیرا خط لوله تشخیص اساساً یک شبکه است. به آن به عنوان یک شبکه طبقه بندی تصویر فکر کنید.
از آنجایی که این شبکه به گونهای طراحی شده است که به روشی انتها به انتها شبیه به طبقهبندی تصویر آموزش دهد، معماری بسیار سریع است و مدل پایه YOLO تصاویر را با سرعت 45 فریم در ثانیه (فریم در ثانیه) پیشبینی میکند که بر روی یک پردازنده گرافیکی Titan X محک زده شده است. نویسندگان همچنین نسخه بسیار سبک تری از YOLO به نام Fast YOLO را ارائه کردند که دارای لایه های کمتری است که تصاویر را با سرعت 155 فریم بر ثانیه پردازش می کند. آیا این شگفت انگیز نیست؟
همانطور که در جدول 1 نشان داده شده است، YOLO به 63.4 mAP (میانگین دقت متوسط) دست یافت که بیش از دو برابر دیگر آشکارسازهای بلادرنگ است و آن را حتی خاص تر می کند. می بینیم که YOLO و Fast YOLO هر دو از انواع آشکارساز شی بلادرنگ DPM با اختلاف قابل توجهی از نظر میانگین دقت متوسط (تقریباً 2x) و FPS بهتر عمل می کنند
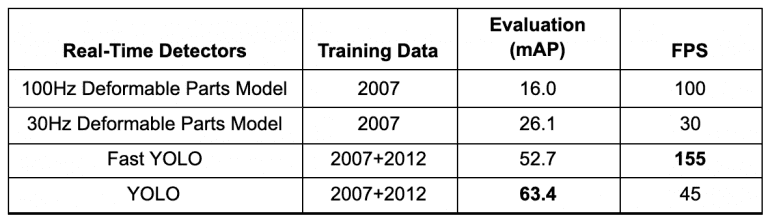
جدول 1: معیارهای کمی آشکارسازهای زمان واقعی (منبع: Redmon et al., p. 6 ).
YOLOv2
ردمون و فرهادی (2017) مقاله YOLO9000: Better, Faster, Stronger را در کنفرانس CVPR منتشر کردند. نویسندگان دو نوع پیشرفته YOLO را در این مقاله پیشنهاد کردند: YOLOv2 و YOLO9000. هر دو یکسان بودند اما در استراتژی آموزشی متفاوت بودند.
YOLOv2 در مجموعه داده های تشخیص مانند Pascal VOC و MS COCO آموزش دیده است. در همان زمان، YOLO9000 برای پیشبینی بیش از 9000 دسته شی مختلف با آموزش مشترک آن بر روی مجموعه دادههای MS COCO و ImageNet طراحی شد.
مدل بهبودیافته YOLOv2 از تکنیکهای جدید مختلفی برای پیشی گرفتن از روشهای پیشرفته مانند Faster-RCNN و SSD در سرعت و دقت استفاده کرد. یکی از این تکنیکها آموزش چند مقیاسی بود که به شبکه اجازه میداد در اندازههای ورودی مختلف پیشبینی کند، بنابراین امکان دادوستد بین سرعت و دقت را فراهم میکرد.
با وضوح ورودی 416×416، YOLOv2 به 76.8 mAP در مجموعه داده VOC 2007 و 67 FPS در Titan X GPU دست یافت. در همان مجموعه داده با ورودی 544×544، YOLOv2 به 78.6 mAP و 40 FPS رسید.
شکل 10 معیار YOLOv2 را در رزولوشن های مختلف روی یک GPU Titan X به همراه سایر معماری های تشخیص مانند Faster R-CNN، YOLOv1، SSD نشان می دهد. ما میتوانیم مشاهده کنیم که تقریباً همه انواع YOLOv2 از نظر سرعت یا دقت بهتر از سایر چارچوبهای تشخیص عمل میکنند، و یک مبادله شدید بین دقت (mAP) و FPS را میتوان در YOLOv2 مشاهده کرد.
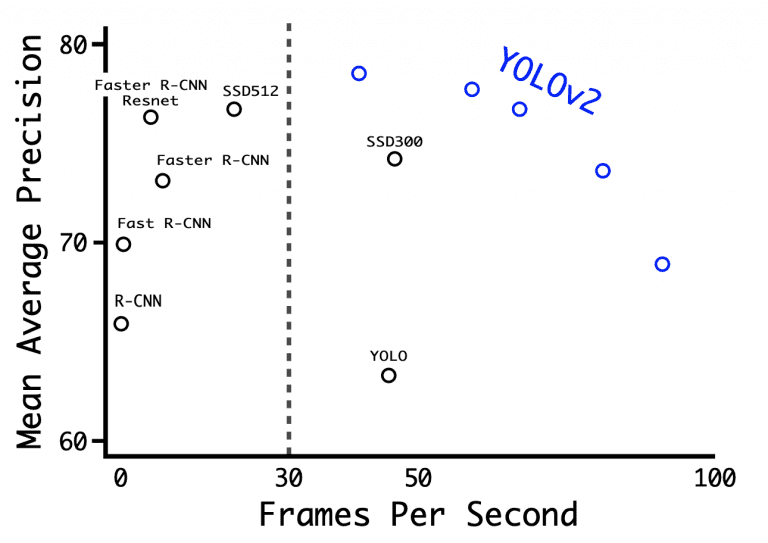
شکل 10: دقت و سرعت در Pascal VOC 2007 (منبع: Redmon and Farhadi, p. 7266 ).
YOLOv3
ردمون و فرهادی (2018) مقاله YOLOv3: An Incremental Improvement را در arXiv منتشر کردند. نویسندگان تغییرات زیادی در طراحی در مورد معماری شبکه ایجاد کردند و بسیاری از تکنیک های دیگر را از YOLOv1 و به خصوص YOLOv2 اقتباس کردند.
این مقاله معماری شبکه جدیدی به نام Darknet-53 را معرفی کرد. Darknet-53 یک شبکه بسیار بزرگتر از قبل است و بسیار دقیق تر و سریعتر است. با وضوح تصویر مختلف مانند 320×320، 416×416 آموزش داده شده است. در رزولوشن 320×320، YOLOv3 به سرعت 28.2 mAP با سرعت 45 فریم در ثانیه روی پردازنده گرافیکی Titan X میرسد و به دقت آشکارساز تکشات (SSD321) است اما 3 برابر سریعتر است (نشان داده شده در شکل 11 ).
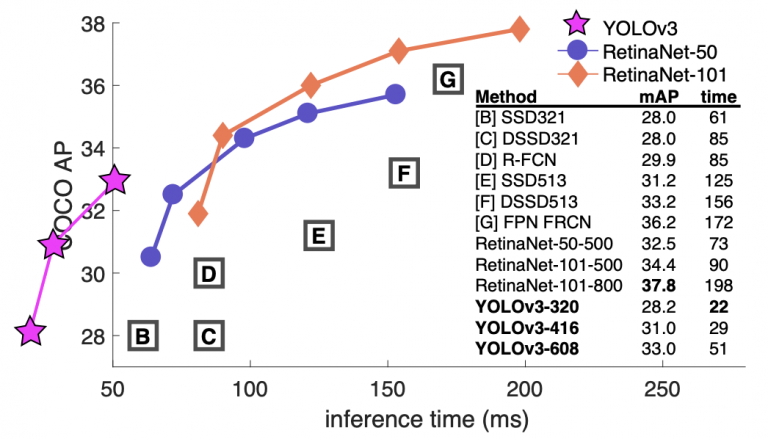
شکل 11: معیار کمی نشان دهنده دقت (COCO mAP) در مقابل زمان استنتاج (ms) (منبع: Redmon and Farhadi, 2018, p. 1 ).
YOLOv4
YOLOv4 محصول بسیاری از آزمایشها و مطالعات است که تکنیکهای جدید کوچک مختلفی را ترکیب میکند که دقت و سرعت شبکه عصبی کانولوشن را بهبود میبخشد.
این مقاله آزمایشهای گستردهای را در معماریهای مختلف GPU انجام داد و نشان داد که YOLOv4 از نظر سرعت و دقت از تمام معماریهای شبکه تشخیص اشیاء دیگر بهتر عمل میکند.
در سال 2020، بوچکوفسکی و همکاران. (نویسنده یک مخزن معروف GitHub: Darknet) مقاله YOLOv4: سرعت و دقت بهینه تشخیص اشیا را در arXiv منتشر کرد. ما می توانیم از شکل 12 مشاهده کنیم که YOLOv4 دو برابر سریعتر از EfficientDet با عملکرد قابل مقایسه اجرا می شود و mAP و FPS YOLOv3 را 10% و 12% بهبود می بخشد.
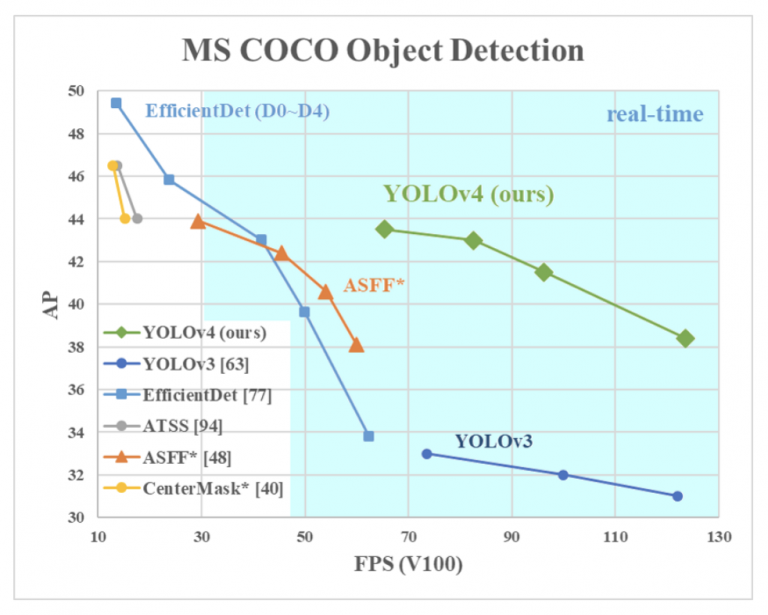
شکل 12: مقایسه YOLOv4 پیشنهادی و دیگر آشکارسازهای شیء پیشرفته (منبع: Bochkovskiy et al., p. 1 ).
عملکرد شبکه عصبی کانولوشن (CNN) تا حد زیادی به ویژگی هایی که استفاده می کنیم و ترکیب می کنیم بستگی دارد. به عنوان مثال، برخی از ویژگی ها فقط بر روی یک مدل خاص، بیان مسئله و مجموعه داده کار می کنند. اما ویژگی هایی مانند نرمال سازی دسته ای و اتصالات باقیمانده برای اکثر مدل ها، وظایف و مجموعه داده ها اعمال می شود. بنابراین، این ویژگی ها را می توان جهانی نامید.
بوچکوفسکی و همکاران از این ایده استفاده کنید و چند ویژگی جهانی را در نظر بگیرید، از جمله
- اتصالات وزنی باقیمانده (WRC)
- اتصالات جزئی متقاطع (CSP)
- متقاطع مینی دسته ای عادی (CmBN)
- آموزش خود خصمانه (SAT)
- فعال سازی میش
- تقویت داده های موزاییکی
- تنظیم DropBlock
- از دست دادن CIoU
ویژگی های فوق برای دستیابی به نتایج پیشرفته ترکیب شده اند: 43.5% mAP (65.7% mAP50) در مجموعه داده MS COCO با سرعت واقعی ~65 FPS در GPU Tesla V100.
مدل YOLOv4 ویژگیهای بالا و بیشتر را ترکیب کرد تا “کیف مجانی” را برای بهبود آموزش مدل و “کیف ویژه” را برای بهبود دقت آشکارساز شی تشکیل دهد.
YOLOv5
در سال 2020، پس از انتشار YOLOv4، تنها در عرض دو ماه، گلن جوچر، بنیانگذار و مدیر عامل Ultralytics ، اجرای متن باز YOLOv5 خود را در GitHub منتشر کرد. YOLOv5 خانواده ای از معماری های تشخیص اشیا را ارائه می دهد که از قبل بر روی مجموعه داده MS COCO آموزش دیده اند. به دنبال آن EfficientDet و YOLOv4 منتشر شد. این تنها آشکارساز شی YOLO است که مقاله تحقیقاتی ندارد که در ابتدا منجر به بحثهایی شد. با این حال، به زودی، این تصور شکسته شد زیرا قابلیت های آن صداها را تضعیف می کرد.
امروزه YOLOv5 یکی از جدیدترین مدل های رسمی با پشتیبانی فوق العاده است و استفاده از آن در تولید آسان تر است. بهترین بخش این است که YOLOv5 به صورت بومی در PyTorch پیاده سازی شده است و محدودیت های چارچوب Darknet را از بین می برد (بر اساس زبان برنامه نویسی C و با دیدگاه محیط های تولید ساخته نشده است). چارچوب Darknet در طول زمان تکامل یافته است و یک چارچوب تحقیقاتی عالی برای کار، آموزش، تنظیم دقیق، استنتاج با TensorRT است. همه اینها با دارک نت امکان پذیر است. با این حال، جامعه کوچکتری دارد و از این رو، حمایت کمتری دارد.
این تغییر عظیم YOLO در PyTorch، تغییر معماری و صادرات به بسیاری از محیطهای استقرار را برای توسعهدهندگان آسانتر کرد. و فراموش نکنیم، YOLOv5 یکی از بهترین مدلهای رسمی است که در ویترین Torch Hub میزبانی میشود.
در زمان انتشار، YOLOv5 در میان تمام پیادهسازیهای شناخته شده YOLO یکی از بهترینها بود. از زمان انتشار YOLOv5، این مخزن بسیار فعال بوده و از زمان انتشار YOLOv5-v1.0 بیش از 90 مشارکت کننده داشته است.
مخزن YOLOv5 از منظر توسعه بسیار قابل ارائه است، که آموزش، تنظیم دقیق، آزمایش و استقرار آن را در پلتفرم های مختلف هدف بسیار آسان تر می کند. برخی از آموزش های خارج از جعبه ارائه شده توسط آنها عبارتند از:
- آموزش مجموعه داده های سفارشی
- آموزش چند پردازنده گرافیکی
- صادرات مدل YOLOv5 آموزش دیده در TensorRT، CoreML، ONNX و TFLite
- هرس کردن معماری YOLOv5
- استقرار با TensorRT
علاوه بر این، آنها یک برنامه iOS به نام iDetection توسعه داده اند که چهار نوع YOLOv5 را ارائه می دهد. ما برنامه را روی iPhone 13 Pro آزمایش کردیم و نتایج چشمگیر بود. این مدل تشخیص را با سرعت 30 فریم بر ثانیه اجرا می کند.
همانند YOLOv4، YOLO v5 از اتصالات جزئی Cross-Stage با Darknet-53 در Backbone و Path Aggregation Network به عنوان Neck استفاده می کند. پیشرفتهای عمده شامل تقویت دادههای موزاییکی جدید (از پیادهسازی YOLOv3 PyTorch) و لنگرهای جعبهای محدودکننده یادگیری خودکار است.
افزایش داده های موزاییکی
ایده تقویت داده های موزاییکی برای اولین بار در پیاده سازی YOLOv3 PyTorch توسط Glenn Jocher مورد استفاده قرار گرفت و اکنون در YOLOv5 استفاده می شود. همانطور که در شکل 13 نشان داده شده است، تقویت موزاییک چهار تصویر آموزشی را به یک تصویر در نسبت های خاص بخیه می زند . تقویت موزاییک مخصوصاً برای معیار تشخیص اشیاء COCO محبوب مفید است، و به مدل کمک میکند تا حل «مشکل اشیای کوچک» معروف را بیاموزد – جایی که اشیاء کوچک به اندازه اجسام بزرگتر با دقت تشخیص داده نمیشوند.
مزیت استفاده از افزایش داده های موزاییکی است
- شبکه اطلاعات زمینه بیشتری را در یک تصویر و حتی خارج از زمینه عادی خود می بیند.
- به مدل اجازه می دهد تا نحوه شناسایی اشیاء را در مقیاس کوچکتر از حد معمول بیاموزد.
- نرمال سازی دسته ای کاهش 4 برابری خواهد داشت زیرا آمار فعال سازی را برای چهار تصویر مختلف در هر لایه محاسبه می کند. این امر نیاز به اندازه کوچک دسته ای بزرگ را در طول تمرین کاهش می دهد.

شکل 13: موزاییک یک روش جدید افزایش داده را نشان می دهد (منبع: Bochkovskiy و همکاران، 2020 ).
معیار کمی
در جدول 2 ، معیارهای عملکرد (mAP) و سرعت (FPS) پنج نوع YOLOv5 را در مجموعه داده اعتبارسنجی MS COCO با وضوح تصویر 640×640 روی Volta 100 GPU نشان میدهیم. هر پنج مدل بر روی مجموعه داده آموزشی MS COC آموزش دیدند. معیارهای مدل به ترتیب صعودی نشان داده شدهاند که با YOLOv5n شروع میشود (یعنی نوع نانو دارای کوچکترین ردپای مدل تا بزرگترین مدل، YOLOv5x).
YOLOv5l را در نظر بگیرید. سرعت استنتاج 10.1ms (یا 100 FPS) با اندازه دسته ای = 1 و 67.2 mAP در 0.5 IOU را به دست می آورد. در مقابل، YOLOv4 با وضوح 608 در V100 به سرعت استنتاج 62 FPS با 65.7 mAP در 0.5 IOU دست یافت. YOLOv5 برنده واضح اینجاست زیرا بهترین عملکرد و حتی سرعت بهتر از YOLOv4 را ارائه می دهد.
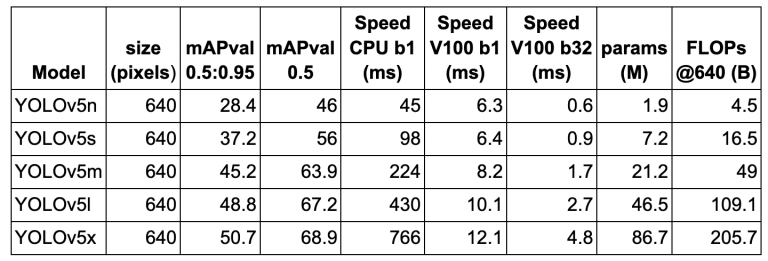
جدول 2: معیارهای عملکرد و سرعت پنج نوع YOLOv5 در مجموعه داده MS COCO.
انتشار نانو YOLOv5
در اکتبر 2021، YOLOv5-v6.0 با ترکیب بسیاری از ویژگیهای جدید و رفع اشکال ( 465 PR از 73 مشارکتکننده )، با تغییراتی در معماری و معرفی مدلهای جدید P5 و P6 Nano منتشر شد: YOLOv5n و YOLOv5n6. مدلهای نانو ~75%پارامترهای کمتری از 7.5 تا 1.9 میلیون نسبت به مدلهای قبلی دارند، به اندازهای کوچک که میتوان روی موبایل و CPU اجرا کرد (نشان داده شده در شکل 14 ). از شکل زیر، همچنین مشهود است که YOLOv5 با حاشیه های قابل توجهی از انواع EfficientDet بهتر عمل می کند. علاوه بر این، حتی کوچکترین نوع YOLOv5 (یعنی YOLOv5n6) به دقت قابل مقایسه بسیار سریعتر از EfficientDet دست می یابد.
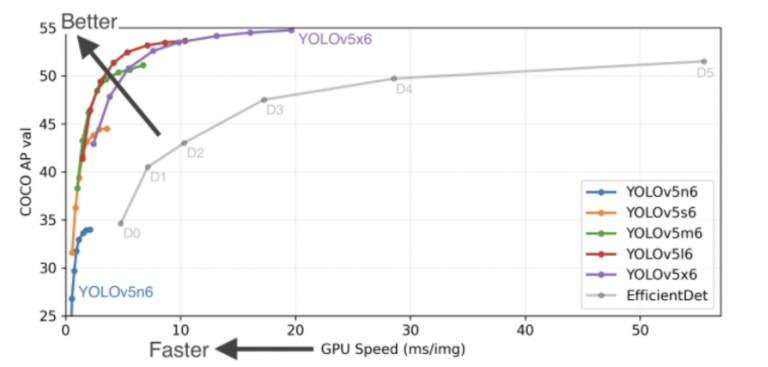
شکل 14: معیارهای عملکرد و سرعت برای مدل های خانواده YOLOv5-v6.0 در مجموعه داده MS COCO، معیارهای رسمی شامل YOLOv5n6 در 1666 FPS (رزولوشن تصویر 640×640 با اندازه دسته ای 32 در پردازنده گرافیکی Tesla v100) است.
YOLOv5n در مقایسه با YOLOv4-Tiny
از آنجایی که YOLOv5n کوچکترین نوع YOLOv5 است، آن را با YOLOv4-Tiny مقایسه می کنیم که سبک ترین نوع مدل YOLOv4 نیز می باشد. شکل 15 نشان می دهد که نوع نانوی YOLOv5 از نظر زمان و دقت آموزش به صورت دستی بهتر از YOLOv4-Tiny است.
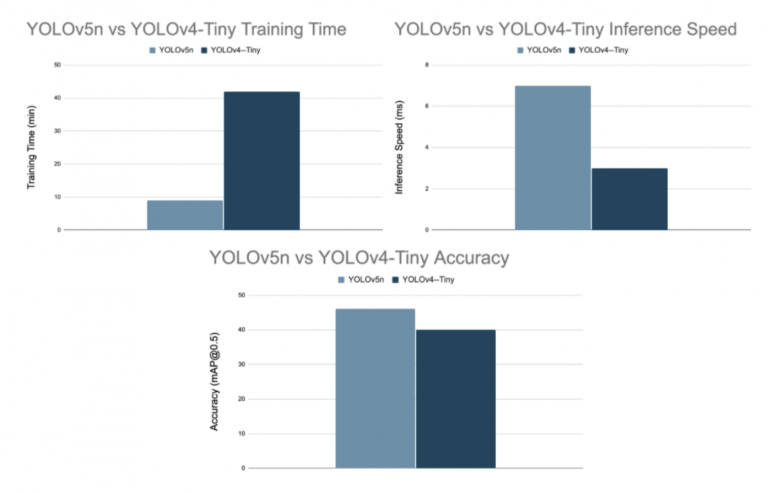
شکل 15: معیارهای YOLOv5n و YOLOv4-Tiny ( منبع ).
PP-YOLO
تاکنون YOLO را در دو فریمورک مختلف یعنی Darknet و PyTorch دیده ایم. با این حال، چارچوب سومی وجود دارد که در آن YOLO به نام چارچوب PaddlePaddle پیاده سازی شده است، از این رو PP-YOLO نامیده می شود . PaddlePaddle یک چارچوب یادگیری عمیق است که توسط بایدو نوشته شده است، که دارای مخزن عظیمی از مدل های Computer Vision و پردازش زبان طبیعی است.
تقریباً چهار ماه پس از انتشار YOLOv4، در آگوست 2020، محققان Baidu ( Long et al. ) PP-YOLO: An Effective and Efficient Implementation of Object Detector را منتشر کردند. مشابه YOLOv4، آشکارساز شی PP-YOLO نیز بر اساس معماری YOLOv3 ساخته شده است.
Paddle Detection
PP-YOLO بخشی از PaddleDetection است، یک کیت توسعه تشخیص شیء سرتاسر (نشان داده شده در شکل 16 ) بر اساس چارچوب PaddlePaddle. بسیاری از معماریهای تشخیص اشیا، ستون فقرات، تکنیکهای تقویت دادهها، مؤلفهها (مانند تلفات، شبکه هرمی ویژگی و غیره) را ارائه میکند که میتوانند در پیکربندیهای مختلف ترکیب شوند تا بهترین شبکه تشخیص اشیا را طراحی کنند.
به طور خلاصه، قابلیتهای پردازش تصویر مانند تشخیص شی، تقسیمبندی نمونه، ردیابی چند شی، تشخیص نقطه کلید را ارائه میکند که فرآیند تشخیص اشیا در ساخت، آموزش، بهینهسازی و استقرار این مدلها را به روشی سریعتر و بهتر تسهیل میکند.
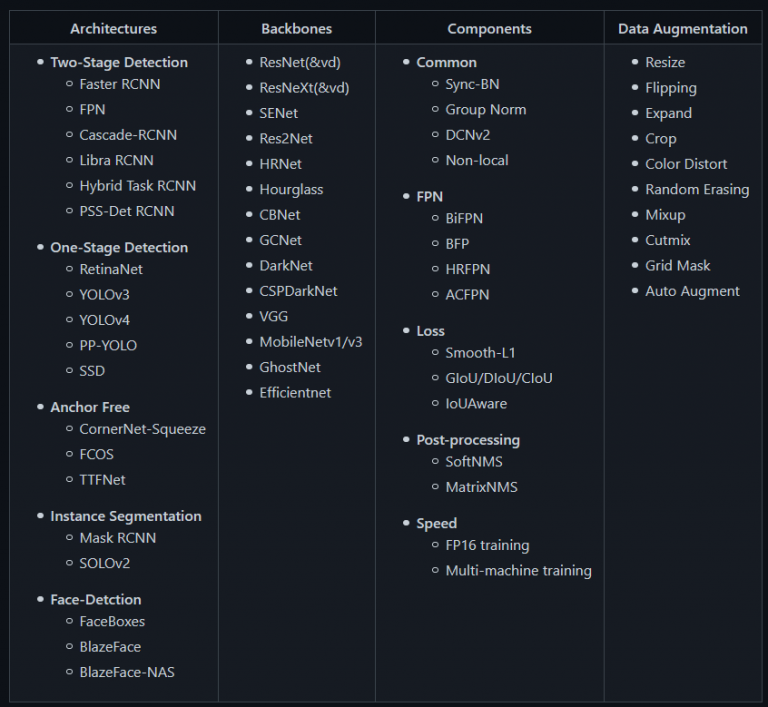
شکل 16: نمای کلی ساختار کیت توسعه ( منبع ).
حالا بیایید به مقاله PP-YOLO برگردیم.
هدف مقاله PP-YOLO انتشار یک مدل تشخیص شی جدید نبود، بلکه یک آشکارساز شی با اثربخشی و کارایی نسبتاً متعادل است که می تواند مستقیماً در سناریوهای کاربردی واقعی اعمال شود. و این هدف با انگیزه کیت توسعه PaddleDetection همخوانی دارد. از این رو، نکته جدید این است که ثابت کنیم مجموعه این ترفندها و تکنیکها، اثربخشی و کارایی را بهتر متعادل میکند و یک مطالعه فرسایشی در مورد اینکه هر مرحله چقدر به آشکارساز کمک میکند، ارائه میکند.
مشابه YOLOv4، این مقاله همچنین سعی میکند ترفندهای مختلف موجود را ترکیب کند که تعداد پارامترهای مدل و FLOP را افزایش نمیدهد، اما دقت آشکارساز را تا حد امکان بهبود میبخشد و اطمینان میدهد که سرعت آشکارساز تقریباً بدون تغییر است. با این حال، بر خلاف YOLOv4، این مقاله شبکههای ستون فقرات مختلف (Darknet-53، ResNext50) و روشهای تقویت دادهها را بررسی نکرد، و از جستجوی معماری عصبی (NAS) برای جستجوی فراپارامترهای مدل استفاده نکرد.
عملکرد PP-YOLO
و با ترکیب همه ترفندها و تکنیک ها، هنگام آزمایش بر روی یک GPU Volta 100 با اندازه دسته ای = 1، PP-YOLO به 45.2% mAP و سرعت استنتاج 72.9 FPS (نشان داده شده در شکل 17 ) دست می یابد، که نشان دهنده تعادل بهتر بین اثربخشی و راندمان، پیشی گرفتن از آشکارسازهای معروف پیشرفته مانند EfficientDet، YOLOv4 و RetinaNet.
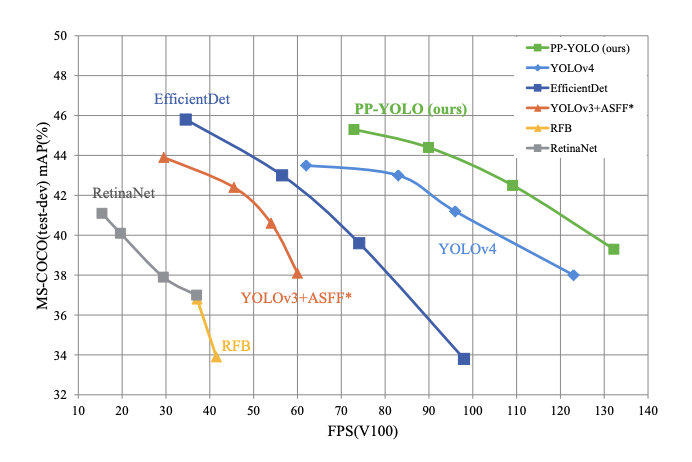
شکل 17: مقایسه PP-YOLO پیشنهادی با دیگر آشکارسازهای شیء پیشرفته. PP-YOLO سریعتر ( x – axis) از YOLOv4 اجرا می شود و mAP ( y – axis) را از 43.5% به 45.2% بهبود می بخشد.
معماری PP-YOLO
مدلهای تشخیص تک مرحلهای معمولاً از ستون فقرات، گردن تشخیص و سر تشخیص تشکیل شدهاند. معماری PP-YOLO (نشان داده شده در شکل 18 ) کاملاً شبیه مدل های تشخیص YOLOv3 و YOLO4 است.
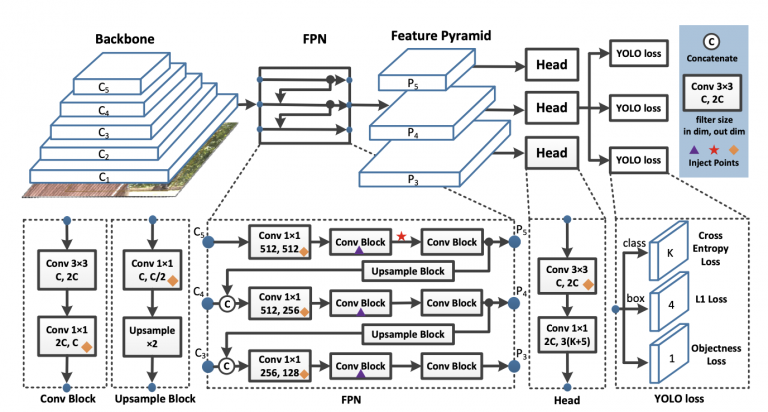
شکل 18: نمودار معماری PP-YOLO متشکل از ستون فقرات، گردن و سر ( منبع ).
آشکارساز PP-YOLO به سه بخش تقسیم می شود:
- ستون فقرات: ستون فقرات در آشکارساز شی یک شبکه کاملاً پیچیده است که به استخراج نقشه های ویژگی از تصویر کمک می کند. از نظر روحی شبیه به یک مدل طبقه بندی تصویر از پیش آموزش دیده است. به جای استفاده از معماری Darknet-53 (در YOLOv3 و YOLOv4)، مدل پیشنهادی از ResNet50-vd-dcn به عنوان ستون فقرات استفاده کرد.در مدل ستون فقرات پیشنهادی، لایه پیچشی 3×3 با پیچشهای تغییر شکلپذیر در آخرین مرحله معماری جایگزین میشود. تعداد پارامترها و FLOPهای ResNet50-vd بسیار کمتر از Darknet-53 است. این به دستیابی به mAP کمی بالاتر از 39.1 در مقایسه با YOLOv3 کمک کرد.
- Detection Neck : شبکه هرمی ویژگی (FPN) هرمی از ویژگی ها را با اتصالات جانبی بین نقشه های ویژگی ایجاد می کند. اگر به شکل زیر دقت کنید، نقشه های ویژگی از مراحل C3، C4 و C5 به عنوان ورودی به ماژول FPN وارد می شوند.
- Detection Head : سر تشخیص آخرین قسمت خط لوله تشخیص شی است که جعبه مرزی (محلی سازی) و طبقه بندی اشیاء را پیش بینی می کند. سر PP-YOLO همان سر YOLOv3 است. برای پیش بینی خروجی نهایی از یک لایه پیچشی 3×3 و به دنبال آن یک لایه پیچشی 1×1 استفاده می شود.کانال های خروجی خروجی نهایی هستند، جایی که تعداد کلاس ها (80 برای مجموعه داده MS COCO)، 3 تعداد لنگرها در هر شبکه است. برای هر لنگر، اولین کانال K احتمالات کلاس پیشبینی، چهار کانال پیشبینی مختصات جعبه مرزی، و یک کانال پیشبینی امتیاز شیئی است.
در معماری PP-YOLO فوق، نقاط تزریق الماس نشاندهنده لایههای coord-conv هستند، مثلثهای بنفش نشاندهنده DropBlocks، و علامت ستاره قرمز نشاندهنده ادغام هرم فضایی است.
گزیده ای از ترفندها و تکنیک ها
اگر به خاطر داشته باشید، بحث کردیم که این مقاله ترفندها و تکنیک های مختلفی را برای طراحی یک شبکه تشخیص اشیاء موثر و کارآمد ترکیب می کند. اکنون به طور مختصر به بررسی هر یک از آنها می پردازیم. این ترفندها همگی در حال حاضر وجود دارند و از مقالات مختلف می آیند.
- اندازه دسته بزرگتر: استفاده از اندازه دسته بزرگتر به تثبیت آموزش کمک می کند و به مدل اجازه می دهد نتایج بهتری تولید کند. سایز دسته ای از 64 به 192 تغییر یافته و بر این اساس نرخ یادگیری و برنامه آموزشی نیز به روز می شود.
- میانگین متحرک نمایی: نویسندگان ادعا می کنند که استفاده از میانگین های متحرک پارامترهای آموزش دیده نتایج بهتری را در طول استنتاج ایجاد می کند.
- منظمسازی DropBlock: این تکنیکی شبیه به تنظیم Dropout است که برای جلوگیری از نصب بیش از حد استفاده میشود. با این حال، در تنظیم بلوک Dropout، نقاط ویژگی حذف شده دیگر به طور تصادفی پخش نمی شوند، بلکه در بلوک ها ترکیب می شوند و کل بلوک حذف می شود. بنابراین، این یک خروج ساختار یافته است که در آن نورونهای نواحی مجاور یک نقشه ویژگی با هم رها میشوند، همانطور که در شکل 19 نشان داده شده است.
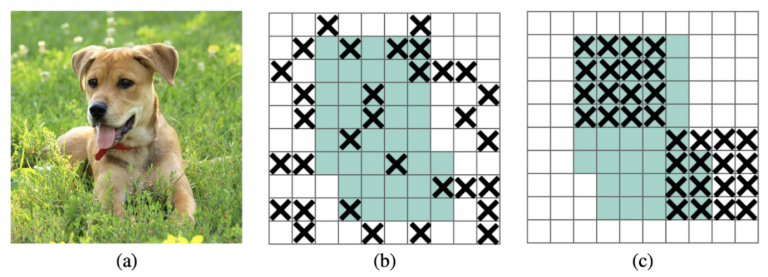
شکل 19: (الف) تصویر ورودی به یک شبکه عصبی کانولوشن. مناطق سبز رنگ در (b) و (c) شامل واحدهای فعال سازی است که حاوی اطلاعات معنایی در تصویر ورودی ( منبع ) است.
در PP-YOLO، DropBlock فقط در هد تشخیص (یعنی FPN) اعمال می شود زیرا افزودن آن به ستون فقرات باعث کاهش عملکرد مدل می شود.
- تقاطع بیش از اتحادیه (IoU) Loss: یک ضرر اضافی (یعنی ضرر IoU) برای آموزش مدل اضافه می شود، در حالی که از دست دادن L1 موجود در YOLOv3 استفاده می شود و اکثر معماری های YOLO جایگزین نمی شوند. یک شاخه اضافی برای محاسبه ضرر IoU اضافه می شود. این کار از آنجایی انجام می شود که متریک ارزیابی mAP به شدت به IoU متکی است.
- IoU Aware: از آنجایی که دقت محلی سازی در اطمینان تشخیص نهایی در نظر گرفته نمی شود، یک شاخه پیش بینی IoU برای اندازه گیری دقت محلی سازی اضافه می شود. در حالی که در طول استنتاج، امتیاز IoU پیشبینیشده در امتیاز احتمال طبقهبندی و نمره عینیت ضرب میشود تا اطمینان تشخیص نهایی پیشبینی شود.
- ماتریس غیر حداکثری سرکوب (NMS): اجرای موازی یک نسخه نرم افزاری NMS سریعتر از NMS سنتی استفاده می شود و هیچ گونه از دست دادن کارایی را به همراه ندارد. NMS نرم به صورت متوالی کار می کند و نمی تواند به صورت موازی اجرا شود.
- لایه ادغام هرم فضایی (SPP): لایه SPP پیاده سازی شده در YOLOv4 در PP-YOLO نیز اعمال می شود اما فقط در نقشه ویژگی بالا. افزودن SPP 2% از پارامترهای مدل و 1% FLOPS را اضافه میکند، اما این به مدل امکان میدهد میدان دریافتی ویژگی را افزایش دهد.
- مدل Pretrained Better: یک مدل از پیش آموزش دیده با دقت طبقه بندی بهتر در ImageNet استفاده می شود که در نتیجه عملکرد تشخیص بهتری دارد. یک مدل ResNet50-vd مقطر به عنوان مدل پیش آموزش استفاده می شود.
نتایج
قبلاً در معرفی PP-YOLO، متوجه شدیم که PP-YOLO سریعتر از YOLOv4 اجرا می شود، با میانگین میانگین امتیاز دقت بهتری از 43.5% تا 45.2%. عملکرد دقیق PP-YOLO در جدول 3 نشان داده شده است .
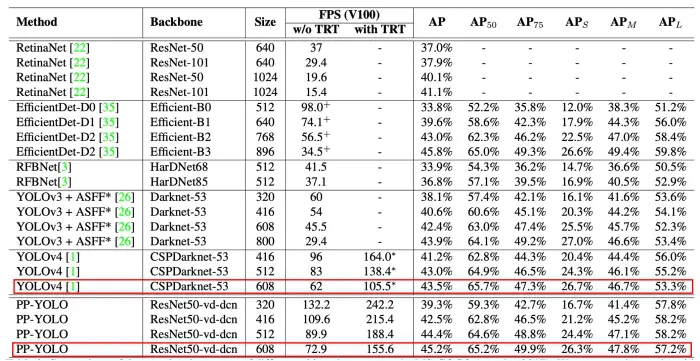
جدول 3: مقایسه دقیق سرعت و دقت PP-YOLO با دیگر آشکارسازهای شیء پیشرفته در MS-COCO (test-dev 2017). نتایج با اندازه دسته = 1، با و بدون TensorRT محاسبه می شود.
لانگ و همکاران (2020) مدل را روی پردازنده گرافیکی Volta 100 با و بدون TensorRT (برای افزایش سرعت استنتاج) مقایسه کرد. از جدول، می توان نتیجه گرفت که در مقایسه با YOLOv4، امتیاز mAP در مجموعه داده MS COCO از 43.5٪ به 45.2٪ افزایش می یابد و FPS از 62 تا 72.9 (بدون TensorRT).
جدول همچنین PP-YOLO را با وضوح تصویر دیگر نشان می دهد و به نظر می رسد که PP-YOLO در تعادل سرعت و دقت در مقایسه با سایر آشکارسازهای پیشرفته برتری دارد.
مطالعه فرسایش
مطالعه فرسایشی انجام شده توسط نویسندگان نشان می دهد که چگونه ترفندها و تکنیک ها بر پارامتر و عملکرد مدل تأثیر می گذارد. در جدول 4 ، PP-YOLO از ردیف دوم با علامت B شروع می شود، جایی که آشکارساز از ResNet50 به عنوان ستون فقرات با پیچش های قابل تغییر شکل استفاده می کند. همانطور که به ردیف بعدی C حرکت می کنید، ترفندهایی به معماری مدل قبلی اضافه می شوند و در کل همان موارد دنبال می شوند. افزایش عملکرد و افزایش پارامترها و FLOPS در ستون های مربوطه نشان داده شده است.
ما به شما توصیه می کنیم برای جزئیات بیشتر مقاله را بررسی کنید.
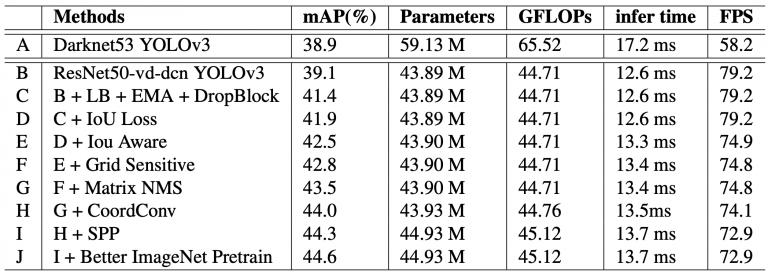
جدول 4: مطالعه ابلیشن تکنیک ها و ترفندها بر روی تقسیم مینیوال MS-COCO.
Scaled-YOLOv4
وانگ و همکاران (2021) مقاله ای با عنوان “Scaled-YOLOv4: Scaling Cross Stage Partial Network” در کنفرانس CVPR منتشر کرد. این مقاله تاکنون بیش از 190 استناد جمع آوری کرده است! با Scaled-YOLOv4، نویسندگان مدل YOLOv4 را با مقیاسبندی کارآمد طراحی و مقیاس شبکه به جلو سوق دادهاند و از پیشرفتهترین EfficientDet قبلی که اوایل امسال توسط تیم تحقیقاتی مغز گوگل منتشر شده بود، پیشی گرفتند.
پیاده سازی Scaled-YOLOv4 در چارچوب PyTorch را می توانید در اینجا بیابید .
شبکه تشخیص پیشنهادی مبتنی بر رویکرد جزئی Cross-Stage هم مقیاسهای بالا و هم پایین را انجام میدهد و معیارهای قبلی مدلهای تشخیص اشیاء کوچک و بزرگ قبلی را در هر دو انتهای سرعت و دقت شکست میدهد. علاوه بر این، رویکرد مقیاسبندی شبکه، عمق، عرض، وضوح و ساختار شبکه را تغییر میدهد.
شکل 20 نشان می دهد که مدل Scaled-YOLOv4-large به نتایج پیشرفته دست می یابد: 55.5% AP (73.4% AP50) برای مجموعه داده MS COCO با سرعت ~16 FPS در GPU Tesla V100.
از سوی دیگر، نسخه سبک تر به نام Scaled-YOLOv4-tiny در حالی که از TensorRT (با نیمه دقیق FP-16) بهینه سازی (اندازه دسته ای) استفاده می کند، به 22.0٪ AP (42.0٪ AP50) با سرعت ~443 FPS در GPU RTX 2080Ti دست می یابد. = 4).
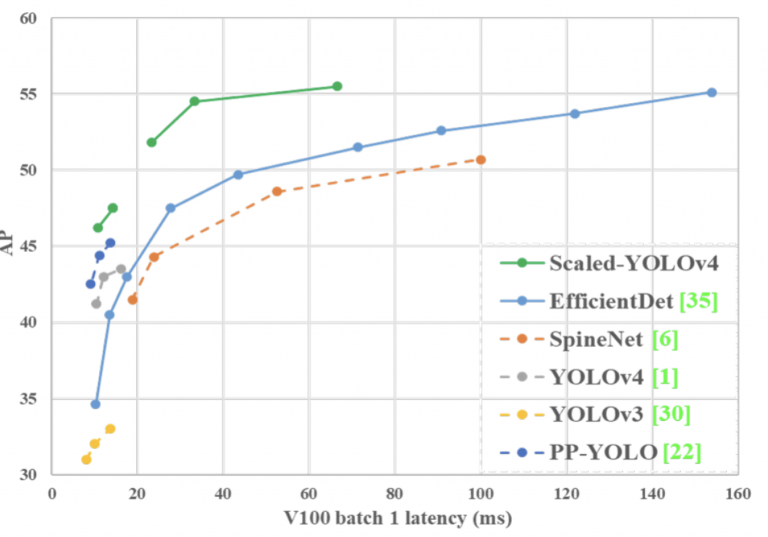
شکل 20: مقایسه Scaled-YOLOv4 پیشنهادی با دیگر آشکارسازهای شیء پیشرفته ( منبع ).
شکل 20 نشان می دهد که Scaled-YOLOv4 بهترین نتایج را در مقایسه با سایر آشکارسازهای پیشرفته به دست می آورد.
مقیاس بندی مدل چیست؟
معماری شبکه عصبی کانولوشن را می توان در سه بعد مقیاس بندی کرد: عمق، عرض و وضوح . عمق شبکه با تعداد لایه های یک شبکه مطابقت دارد. عرض با تعداد فیلترها یا کانال ها در یک لایه کانولوشن مرتبط است . در نهایت، وضوح به سادگی ارتفاع و عرض تصویر ورودی است.
شکل 21 درک شهودی تری از مقیاس بندی مدل در این سه بعد ارائه می دهد که در آن (a) یک مثال شبکه پایه است. (ب) – (د) مقیاس بندی معمولی هستند که فقط یک بعد از عرض، عمق یا وضوح شبکه را افزایش می دهند. و (e) یک روش مقیاس بندی ترکیبی پیشنهادی (در EfficientDet) است که به طور یکنواخت هر سه بعد را با یک نسبت ثابت مقیاس می کند.
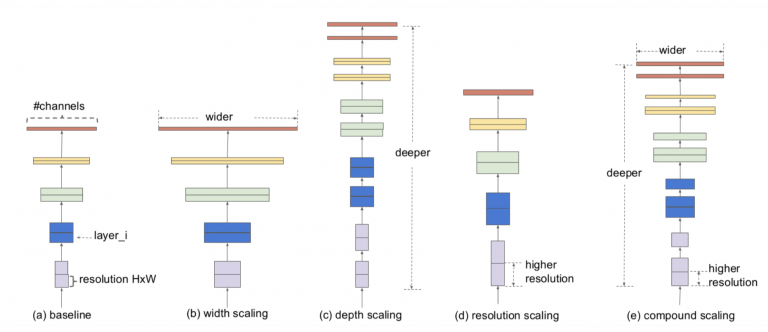
شکل 21: مقیاس بندی مدل در EfficientDet ( منبع ).
روش سنتی مقیاسبندی مدل، تغییر عمق یک مدل است، یعنی افزودن لایههای کانولوشنی بیشتر. به عنوان مثال، VGGNet طراحی شده توسط Simonyan و همکاران. لایه های کانولوشنال اضافی را در مراحل مختلف انباشته کرد و از این مفهوم برای طراحی معماری های VGG-16 و VGG-19 استفاده کرد.
روشهای زیر عموماً از همان روش برای مقیاسبندی مدل پیروی میکنند. اول، معماری ResNet پیشنهاد شده توسط He et al. (2015) از مقیاسبندی عمق برای ساخت شبکههای بسیار عمیق مانند ResNet-50، ResNet-101 استفاده کرد که به شبکه اجازه داد ویژگیهای پیچیدهتری را بیاموزد اما از مشکلات گرادیان ناپدید شدن رنج میبرد. بعدها، Zagoruyko و Komodakis (2017) در مورد عرض شبکه فکر کردند و تعداد هسته های لایه کانولوشن را تغییر دادند تا مقیاس بندی، در نتیجه ResNet گسترده (WRN) را درک کنند، در حالی که همان دقت را حفظ کردند. اگرچه WRN پارامترهای بیشتری نسبت به ResNet داشت، اما سرعت استنتاج بسیار سریعتر بود.
سپس در سالهای اخیر، مقیاسبندی مرکب بهطور یکنواخت تمام ابعاد عمق/عرض/تفکیک یک معماری شبکه عصبی کانولوشنال را با استفاده از یک ضریب ترکیبی مقیاسبندی میکند. بر خلاف روش مرسوم که خودسرانه این عوامل را مقیاس میکند، روش مقیاسبندی مرکب به طور یکنواخت عرض، عمق و وضوح شبکه را با مجموعهای از ضرایب مقیاسبندی ثابت مقیاس میدهد.
و این همان چیزی است که scaled-YOLOv4 نیز سعی می کند انجام دهد، یعنی از تکنیک های مقیاس بندی شبکه بهینه برای دستیابی به شبکه های شناسایی YOLOv4-CSP -> P5 -> P6 -> P7 استفاده می کند.
بهبود در Scaled-YOLOv4 نسبت به YOLOv4
- Scaled-YOLOv4 از تکنیک های مقیاس بندی شبکه بهینه برای دستیابی به شبکه های YOLOv4-CSP -> P5 -> P6 -> P7 استفاده می کند.
- فعالسازیهای اصلاحشده برای عرض و ارتفاع، که امکان آموزش سریعتر شبکه را فراهم میکند.
- معماری شبکه بهبود یافته: Backbone بهینه شده و Neck (Path-Aggregation Network) از اتصالات CSP و فعال سازی Mish استفاده می کند.
- در طول آموزش از میانگین متحرک نمایی (EMA) استفاده می شود.
- برای هر رزولوشن شبکه، یک شبکه مجزا آموزش داده می شود، در حالی که در YOLOv4 شبکه تکی با وضوح های متعدد آموزش داده می شود.
طراحی Scaled-YOLOv4
YOLOv4 با CSP ساخته شده است
YOLOv4 برای تشخیص واقعی اشیا در یک GPU عمومی طراحی شده است. در Scaled-YOLOv4، YOLOv4 دوباره به YOLOv4-CSP طراحی شده است تا بهترین مبادله سرعت/دقت را داشته باشد.
وانگ و همکاران (2021) اغلب در مقاله ذکر شده است که آنها بخش معینی از شبکه تشخیص شی را “CSP” کردند. CSP-ize در اینجا به معنای به کارگیری مفاهیمی است که در مقاله شبکه های جزئی Cross Stage ارائه شده است. CSP روش جدیدی برای معماری شبکه های عصبی کانولوشن است که محاسبات را برای شبکه های مختلف CNN کاهش می دهد: تا 50٪ (برای ستون فقرات Darknet در FLOP).
در یک اتصال CSP:
- نیمی از سیگنال خروجی در امتداد مسیر اصلی قرار می گیرد که به تولید اطلاعات معنایی بیشتر با یک میدان پذیرنده بزرگ کمک می کند.
- نیمه دیگر محورهای سیگنال به حفظ اطلاعات فضایی بیشتر با یک میدان پذیرنده کوچک کمک می کند.
شکل 22 نمونه ای از اتصال CSP را نشان می دهد. در سمت چپ یک شبکه استاندارد است، در حالی که در سمت راست شبکه CSP است.
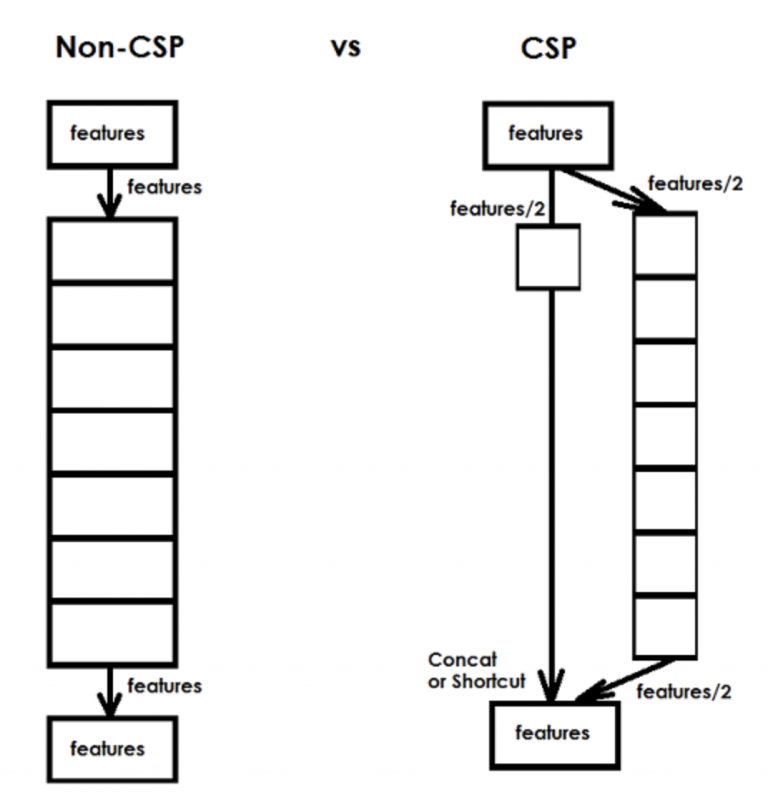
شکل 22: مثالی از اتصال CSP ( منبع ).
مقیاس بندی مدل YOLOv4-Tiny
مدل YOLOv4-tiny ملاحظات متفاوتی نسبت به مدل Scaled-YOLOv4 داشت، زیرا در لبه، محدودیتهای مختلفی مانند پهنای باند حافظه و دسترسی به حافظه وارد عمل میشوند. برای CNN کم عمق YOLOv4-tiny، نویسندگان به OSANet برای پیچیدگی محاسباتی مطلوب آن در عمق کمی نگاه می کنند.
جدول 5 مقایسه عملکرد YOLOv4-tiny را با دیگر آشکارسازهای اشیاء کوچک نشان می دهد. باز هم YOLOv4-tiny بهترین عملکرد را در مقایسه با سایر مدل های کوچک به دست می آورد
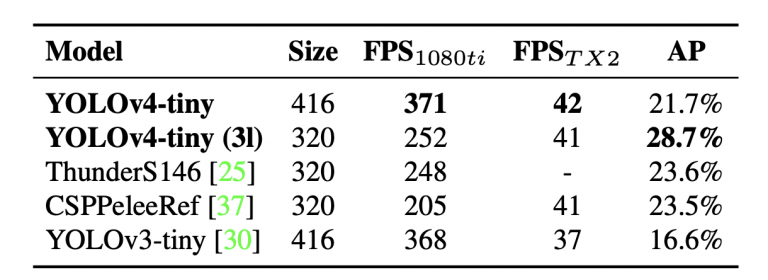
جدول 5: مقایسه مدل های ریز به روز.
جدول 6 نتایج YOLOv4-tiny را هنگام آزمایش بر روی GPU های تعبیه شده مختلف، از جمله Xavier AGX، Xavier NX، Jetson TX2، Jetson NANO نشان می دهد. اگر FP16 و اندازه دسته = 4 برای آزمایش Xavier AGX و Xavier NX اتخاذ شوند ، نرخ فریم می تواند به ترتیب به 290 FPS و 118 FPS برسد .
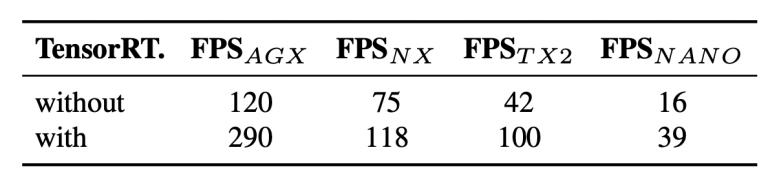 جدول 6: FPS YOLOv4-tiny در دستگاههای تعبیهشده.
جدول 6: FPS YOLOv4-tiny در دستگاههای تعبیهشده.
علاوه بر این، اگر از TensorRT FP16 برای اجرای YOLOv4-tiny بر روی GPU RTX 2080ti عمومی استفاده کنید ، زمانی که اندازه دسته به ترتیب برابر با 1 و 4 باشد، نرخ فریم مربوطه می تواند به 773 FPS و 1774 FPS برسد که بسیار سریع است.
YOLOv4-tiny بدون توجه به اینکه از کدام دستگاه استفاده میشود، میتواند به عملکرد بیدرنگ دست یابد.
مقیاس بندی مدل های YOLOv4-CSP
برای تشخیص اجسام بزرگ در تصاویر بزرگ، نویسندگان دریافتند که افزایش عمق و تعداد مراحل در ستون فقرات و گردن CNN ضروری است (افزایش عرض تأثیر کمی دارد). این به آنها اجازه می دهد ابتدا اندازه ورودی و تعداد مراحل را افزایش دهند و به صورت پویا عرض و عمق را مطابق با الزامات سرعت استنتاج بلادرنگ تنظیم کنند. علاوه بر این عوامل مقیاس، نویسندگان همچنین پیکربندی معماری مدل خود را در مقاله تغییر می دهند.
YOLOv4-large برای پردازشگر گرافیکی ابری طراحی شده است. هدف اصلی دستیابی به دقت بالا برای تشخیص اشیا است. علاوه بر این، یک مدل کاملاً با CSP، YOLOv4-P5، توسعه یافته و تا YOLOv4-P6 و YOLOv4-P7، همانطور که در شکل 23 نشان داده شده است، توسعه یافته است .
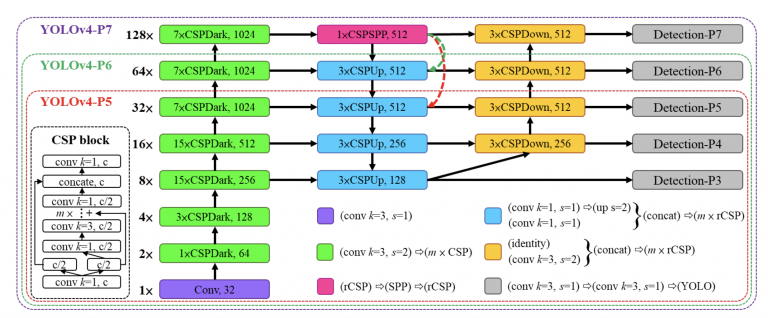
شکل 23: معماری YOLOv4-large، از جمله YOLOv4-P5، YOLOv4-P6، و YOLOv4-P7.
YOLOv4-P6 میتواند در ویدیوها با سرعت 30 فریم در ثانیه به عملکرد همزمان برسد، زمانی که ضریب مقیاسگذاری عرض برابر با 1 باشد. YOLOv4-P7 میتواند عملکرد بیدرنگ را با سرعت 16 فریم در ثانیه در ویدیوها به دست آورد، زمانی که ضریب مقیاس عرض برابر با 1.25 باشد.
افزایش داده ها
افزایش داده ها در YOLOv4 یکی از کمک های کلیدی به عملکرد چشمگیر YOLOv4 بود. در Scaled-YOLOv4، نویسندگان ابتدا روی یک مجموعه داده کمتر تقویت شده آموزش میدهند، سپس در پایان آموزش، تقویتها را برای تنظیم دقیق افزایش میدهند. آنها همچنین از “Test Time Augmentations” استفاده می کنند، که در آن چندین افزایش در مجموعه تست اعمال می شود. سپس پیشبینیها در آن آزمایشهای تقویتشده بهطور میانگین محاسبه میشوند تا نتایج غیرواقعی آنها بیشتر شود.
برای نتیجهگیری، نویسندگان نشان میدهند که شبکه عصبی تشخیص شی YOLOv4 بر اساس رویکرد CSP مقیاسهای بالا و پایین را دارد و برای شبکههای کوچک و بزرگ کاربرد دارد. از این رو، آنها آن را Scaled-YOLOv4 می نامند. علاوه بر این، مدل پیشنهادی (YOLOv4-large) با استفاده از TensorRT-FP16 به بالاترین دقت 56.0% AP در مجموعه داده آزمایشی MS COCO، سرعت بسیار بالا 1774 FPS برای مدل کوچک YOLOv4-tiny RTX 2080Ti و سرعت بهینه دست یافت. و دقت برای سایر مدل های YOLOv4.
تا کنون، ما هفت ردیاب شی YOLO را پوشش دادهایم و میتوان گفت که برای تشخیص شیء، سال 2020 بهترین سال بود و حتی بیشتر از آن برای خانواده YOLO. ما متوجه شدیم که یکی پس از دیگری به پیشرفته ترین روش های تشخیص اشیا توسط YOLOv4، YOLOv5، PP-YOLO و Scaled-YOLOv4 رسیده است.
بیایید اکنون به سراغ آشکارساز YOLO بعدی برویم و ببینیم چه چیزی برای سال 2021 در انتظار است!
PP-YOLOv2
در سال 2021، بایدو نسخه دوم PP-YOLO را با نام PP-YOLOv2: A Practical Object Detector توسط Xing Huang و همکاران منتشر کرد. منتشر شده در arXiv دستیابی به ارتفاعات جدید در حوزه تشخیص اشیا.
از عنوان مقاله، به راحتی می توان استنباط کرد که انگیزه پشت این مقاله ایجاد یک آشکارساز شی بود که به دقت خوبی دست یابد و استنتاج را با سرعت بیشتری انجام دهد. از این رو، یک آشکارساز شی عملی. علاوه بر این، از آنجایی که این مقاله دنبالهای از کار قبلی است (یعنی PP-YOLO)، نویسندگان میخواستند آشکارسازی را بسازند که تعادل کاملی بین اثربخشی و کارایی داشته باشد و برای دستیابی به آن، مشابهی مشابه از ترفندهای ترکیبی و تکنیک ها با تمرکز بر مطالعه فرسایش دنبال شد.
با ترکیب چند اصلاح موثر، PP-YOLOv2 به طور قابل توجهی عملکرد را بهبود بخشید (یعنی از 45.9٪ mAP به 49.5٪ mAP در مجموعه تست MS COCO2017). علاوه بر این، از نظر سرعت، همانطور که در شکل 24 نشان داده شده است، PP-YOLOv2 در 68.9FPS با وضوح تصویر 640×640 اجرا می شود . علاوه بر این، PPYOLOv2 با دو معماری ستون فقرات مختلف معرفی شد: ResNet-50 و ResNet-101، بر خلاف PPYOLOv1، که تنها با ستون فقرات ResNet-50 منتشر شد
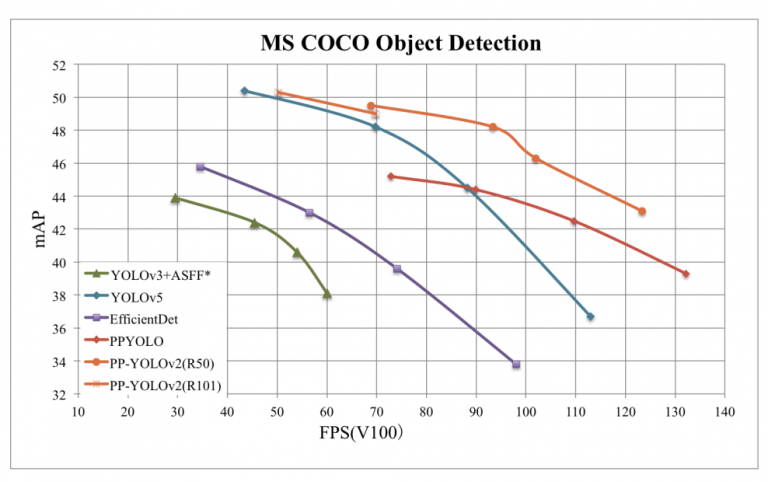
شکل 24: مقایسه PP-YOLOv2 پیشنهادی و آشکارسازهای شیء دیگر.با پشتیبانی از موتور TensorRT، در نیمه دقیق (FP16، اندازه دسته = 1) سرعت استنتاج PP-YOLOv2-ResNet50 را به 106.5 FPS افزایش داد و از دیگر آشکارسازهای شیء پیشرفته مانند YOLOv4-CSP و YOLOv5l با تقریباً همان مقدار پارامترهای مدل.هنگامی که ستون فقرات آشکارساز از ResNet50 به ResNet101 جایگزین شد، PP-YOLOv2 به 50.3% mAP در مجموعه آزمایشی MS COCO2017 دست یافت و عملکرد مشابهی را با YOLOv5x به دست آورد که YOLOv5x را به طور قابل توجهی در سرعت تقریباً 16 درصد شکست داد.بنابراین اکنون میدانید که اگر رئیستان از شما بخواهد روی مشکلی که شامل تشخیص شی است کار کنید، کدام آشکارساز را باید انتخاب کنید. البته اگر قرار باشد KPI با سرعت بسیار بالاتری به عملکرد خوب برسد، پاسخ PP-YOLOv2 خواهد بود :)!
بازبینی PP-YOLO
در حال حاضر، ما می دانیم که PP-YOLOv2 بر اساس پیشرفت های تحقیقاتی انجام شده در مقاله PP-YOLO است، که به عنوان یک مدل پایه برای PP-YOLOv2 عمل می کند.
PP-YOLO یک نسخه پیشرفته از YOLOv3 بود که در آن ستون فقرات با ResNet50-vd از Darknet-53 جایگزین شد. بسیاری از پیشرفتهای دیگر از طریق یک مطالعه دقیق ابلیشن با استفاده از مجموع 10 ترفند، مانند
- تنظیم DropBlock
- پیچش های قابل تغییر شکل
- CoordConv
- ادغام هرم فضایی
- از دست دادن IoU و شاخه
- حساسیت شبکه
- ماتریس NMS
- مدل پیشآموزشی بهتر ImageNet
انتخاب اصلاحات
- شبکه تجمع مسیر (PAN): برای شناسایی اشیا در مقیاس های مختلف، نویسندگان از PAN در گردن شبکه تشخیص اشیا استفاده می کنند. در PP-YOLO، شبکه هرمی ویژگی برای ایجاد مسیرهای پایین به بالا مورد استفاده قرار گرفت. مشابه YOLOv4، در PP-YOLOv2، نویسندگان طراحی PAN را دنبال میکنند تا اطلاعات از بالا به پایین را جمع کنند.
- عملکرد Mish Activation: عملکرد Mish activation در گردن شبکه تشخیص پذیرفته شده است. از آنجایی که PP-YOLOv2 به دلیل دقت بالای 82.4% در مجموعه داده طبقه بندی ImageNet از پارامترهای از پیش آموزش دیده استفاده می کند. در ستون فقرات آشکارسازهای مختلف شیء عملی مانند YOLOv4 و YOLOv5 مؤثر بوده است.
- اندازه ورودی بزرگتر: تشخیص اشیاء کوچکتر اغلب یک چالش است و با عبور تصویر از شبکه، اطلاعات اشیاء در مقیاس کوچک از بین می رود. بنابراین، در PP-YOLOv2، اندازه ورودی افزایش مییابد و مساحت اشیا را بزرگ میکند. در نتیجه عملکرد افزایش خواهد یافت. بزرگترین اندازه ورودی، 608، به 768 افزایش یافته است. از آنجایی که وضوح ورودی بزرگتر حافظه بیشتری را اشغال می کند، بنابراین، اندازه دسته ای از 24 تصویر در هر GPU به 12 تصویر در هر GPU کاهش می یابد که به طور یکنواخت در اندازه های ورودی مختلف طراحی می شود
[320, 352, 384, 416, 448, 480, 512, 544, 576, 608, 640, 672, 704, 736, 768]. - IoU Aware Branch: در PP-YOLO، کاهش آگاهی IoU در قالب وزن نرم و مغایر با هدف اصلی محاسبه می شود. بنابراین در PP-YOLOv2، یک قالب برچسب نرم، عملکرد از دست دادن PP-YOLO را بهتر تنظیم می کند و آن را از همپوشانی بین جعبه های مرزی آگاه تر می کند.
جدول 7 مطالعه فرسایشی اصلاحات در استنباط تقسیم اعتبار MS COCO mini در GPU Volta 100 را نشان می دهد. در جدول، A به مدل پایه PP-YOLO اشاره دارد. سپس، در B ، PAN و Mish به A اضافه می شوند ، که افزایش قابل توجهی از 2 mAP می دهد . اگرچه B کندتر از A است، پرش دقت ارزش آن را دارد.
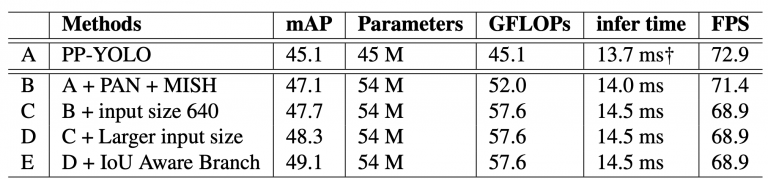
جدول 7: مطالعه فرسایش در PP-YOLOv2 در مجموعه داده MS COCO. “†” نشان می دهد که نتیجه شامل زمان رمزگشایی جعبه محدود (1~2ms) است.
YOLOv4 و YOLOv5 با وضوح تصویر 640 ارزیابی شدند، اندازه ورودی PP-YOLOv2 برای آموزش و ارزیابی به 640 افزایش یافته است تا مقایسه ای منصفانه داشته باشیم (نشان داده شده در C ).
افزایش mAP در D (اندازه ورودی بزرگتر) و E (شاخه آگاه IoU) بدون کاهش زمان استنتاج مشاهده می شود که نشانه خوبی است.
برای اطلاعات دقیق تر در مورد مقایسه سرعت و دقت PP-YOLOv2 با دیگر آشکارسازهای شیء پیشرفته، جدول 2 را در مقاله آنها در arXiv بررسی کنید.
یولو ایکس
در سال 2021، Ge و همکاران. یک گزارش فنی به نام YOLOX: Exceeding YOLO Series در سال 2021 در arXiv منتشر کرد. تاکنون، تنها آشکارساز شیء YOLO بدون لنگر، YOLOv1 بود، اما YOLOX نیز اشیاء را به روشی بدون لنگر تشخیص میدهد. علاوه بر این، سایر تکنیکهای تشخیص پیشرفته مانند سر جدا شده، استفاده از تکنیکهای تقویت داده قوی ، و استراتژی تخصیص برچسب پیشرو SimOTA را برای دستیابی به نتایج پیشرفته انجام میدهد.
YOLOX با استفاده از یک مدل YOLOX-L، مقام اول را در چالش ادراک جریانی (کارگاه آموزشی رانندگی خودمختار که در ارتباط با CVPR 2021 انجام شد) کسب کرد.
همانطور که در شکل 25 (راست) نشان داده شده است، YOLOX-Nano، با تنها 0.91M پارامتر، 25.3% AP در مجموعه داده MS COCO به دست آورد که 1.8% AP از NanoDet پیشی گرفت. افزودن تغییرات مختلف به YOLOv3 دقت را از 44.3% به 47.3% AP در COCO افزایش داد.
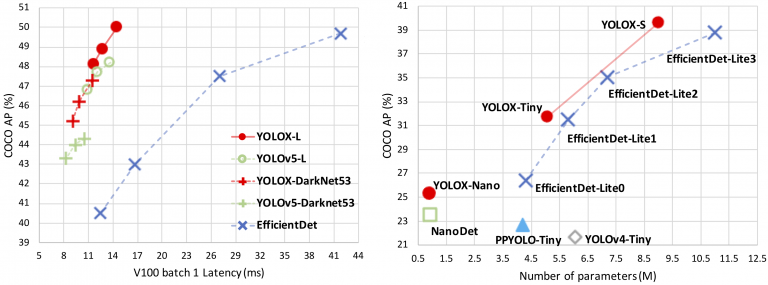
شکل 25: معاوضه سرعت-دقت ( سمت چپ ) و منحنی اندازه-دقت مدل های لایت ( راست ) برای YOLOX و دیگر آشکارسازهای شیء پیشرفته.YOLOX-L به 50.0% AP در COCO با سرعت 68.9 FPS در Tesla V100 با پارامترهای تقریباً مشابه YOLOv4- CSP، YOLOv5-L دست یافت که 1.8% AP از YOLOv5-L فراتر رفت.YOLOX در چارچوب PyTorch پیاده سازی شده و با در نظر گرفتن استفاده عملی توسط توسعه دهندگان و محققان طراحی شده است. بنابراین، نسخههای استقرار YOLOX در چارچوبهای ONNX، TensorRT و OpenVino نیز در دسترس هستند.در طول 2 سال گذشته، پیشرفت های قابل توجهی در دانشگاه های تشخیص اشیا بر روی آشکارسازهای بدون لنگر، استراتژی های تخصیص برچسب پیشرفته و آشکارسازهای انتها به انتها (بدون NMS) متمرکز شده است. با این حال، هیچ یک از این تکنیکها هنوز در معماریهای تشخیص شی YOLO اعمال نشده است، از جمله مدلهای اخیر: YOLOv4، YOLOv5، و PP-YOLO. بسیاری از آنها هنوز آشکارسازهای مبتنی بر لنگر با قوانین تخصیص دست ساز برای آموزش هستند. و این انگیزه پشت انتشار YOLOX است!
YOLOX-Darknet53
YOLOv3 با ستون فقرات Darknet-53 به عنوان خط پایه انتخاب شده است. سپس، یک سری بهبودها در مدل پایه انجام شد.
تنظیمات تمرین در درجه اول از پایه تا مدل نهایی YOLOX مشابه است. همه مدل ها برای 300 دوره در مجموعه داده MS COCO train2017 با اندازه دسته ای 128 آموزش داده شدند. اندازه ورودی به طور مساوی از 448 تا 832 با 32 گام ترسیم شده است. FPS و تأخیر با دقت FP16 (نیمه دقت) و اندازه دسته = 1 در یک واحد پردازشگر گرافیکی Tesla Volta 100 اندازه گیری شد.
YOLOv3-Baseline
از ستون فقرات DarkNet-53 و یک لایه SPP به نام YOLOv3-SPP استفاده می کند. برخی از استراتژی های آموزشی در مقایسه با اجرای اصلی اصلاح شده اند، مانند
- بهروزرسانی وزنهای میانگین متحرک نمایی
- جدول نرخ یادگیری کسینوس
- BCE از دست دادن برای طبقه بندی و شیء شاخه
- IoU Loss برای شاخه رگرسیون
با آن پیشرفتها، خط پایه YOLOv3 به 38.5% AP در مجموعه اعتبارسنجی MS COCO، همانطور که در جدول 8 نشان داده شده است، دست یافت. همه مدل ها با وضوح 640×640، با دقت FP16 و اندازه دسته ای = 1 در تسلا V100 تست شده اند. تأخیر و FPS در جدول زیر بدون پس پردازش اندازه گیری می شود
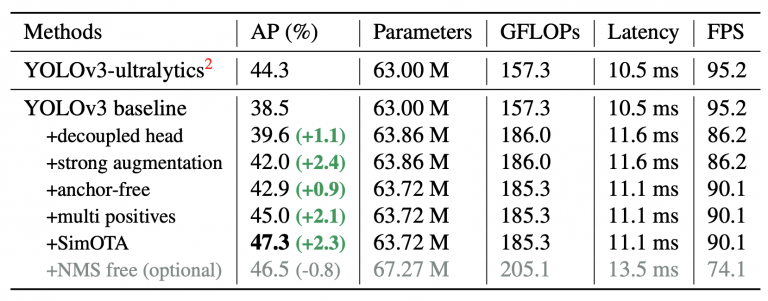
جدول 8: YOLOX-Darknet53 بر حسب AP (%) روی MS COCO val.
سر جدا شده
شکل 26 سر کوپل شده ( بالا ) مورد استفاده در مدل های YOLOv3 به YOLOv5 و سر جداشده ( پایین ) در YOLOX را نشان می دهد. سر در اینجا به معنای پیش بینی خروجی در مقیاس های مختلف است. به عنوان مثال، در سر جفت شده، یک تانسور پیش بینی داریم(توضیحات دقیق در شکل زیر نشان داده شده است). و مشکلی که در این راه وجود دارد این است که معمولاً در حین تمرین وظایف طبقه بندی و بومی سازی را در یک سر داریم که اغلب در حین تمرین با یکدیگر رقابت می کنند. در نتیجه، مدل برای طبقهبندی و محلیسازی صحیح هر شیء در تصویر تلاش میکند.
بنابراین، همانطور که در شکل 26 نشان داده شده است، سر جدا شده برای طبقه بندی و محلی سازی در YOLOX استفاده می شود . برای هر سطح از ویژگی FPN، ابتدا یک لایه تبدیل 1×1 اعمال می شود تا کانال های ویژگی را به 256 کاهش دهد. سپس دو شاخه موازی با دو لایه تبدیل 3×3، به ترتیب برای کارهای طبقه بندی و محلی سازی اضافه می شود. در نهایت یک شاخه IoU اضافی به شاخه محلی سازی اضافه می شود.
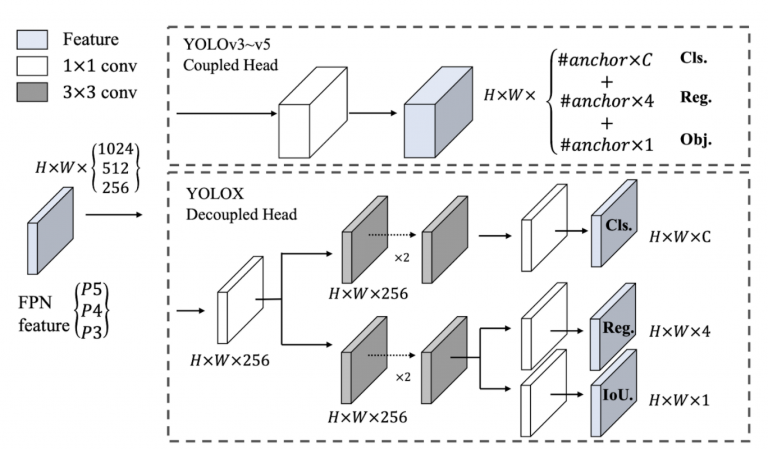
شکل 26: تصویری از تفاوت بین هد YOLOv3 و سر جدا شده پیشنهادی.همانطور که در شکل 27 نشان داده شده است، سر جدا شده به مدل YOLOX اجازه می دهد تا سریعتر از سر کوپل شده همگرا شود . علاوه بر این، در محور x، میتوانیم مشاهده کنیم که چگونه امتیازات COCO AP برای سر جداشده بسیار سریعتر از هد YOLOv3 بهبود مییابد.
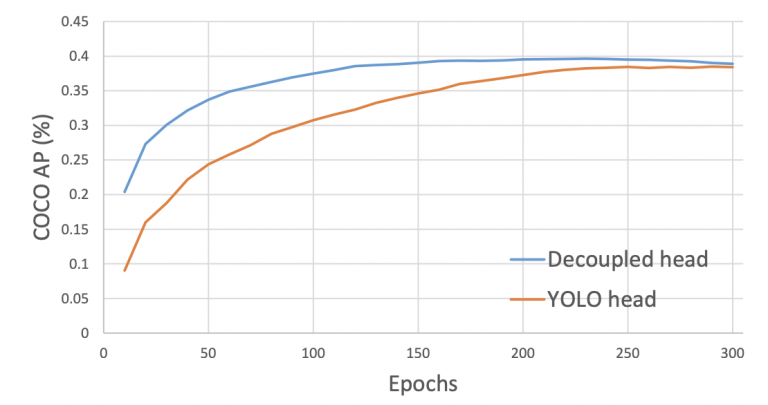 شکل 27: منحنی های آموزشی برای آشکارسازها با YOLOv3 کوپل شده و سر جدا شده YOLOX.
شکل 27: منحنی های آموزشی برای آشکارسازها با YOLOv3 کوپل شده و سر جدا شده YOLOX.
تقویت داده های قوی
تکنیکهای تقویت داده موزاییک و MixUp مشابه YOLOv4 برای افزایش عملکرد YOLOX اضافه شدند. Mosaic یک استراتژی تقویت کارآمد است که توسط ultralytics-YOLOv3 پیشنهاد شده است .
با استفاده از دو تکنیک تقویت فوق، نویسندگان دریافتند که پیشآموزش ستون فقرات در مجموعه داده ImageNet سودمند نیست، بنابراین آنها مدل را از ابتدا آموزش دادند.
تشخیص بدون لنگر
برای توسعه یک آشکارساز شی با سرعت بالا، YOLOX مکانیزم بدون لنگر را اتخاذ کرد که تعداد پارامترهای طراحی را کاهش میدهد، زیرا اکنون دیگر نیازی به کار با جعبههای لنگر نداریم، که تعداد پیشبینیها را به میزان قابل توجهی افزایش داد. و بنابراین، برای هر مکان یا شبکه در سر پیش بینی، ما اکنون به جای پیش بینی خروجی برای سه انکر باکس مختلف، تنها یک پیش بینی داریم. مکان مرکزی هر شی یک نمونه مثبت در نظر گرفته می شود و یک محدوده مقیاس شده از پیش تعریف شده وجود دارد.
به زبان ساده، در تشخیص بدون لنگر، پیشبینیهای هر شبکه از 3 به 1 کاهش مییابد و مستقیماً چهار مقدار را پیشبینی میکند، یعنی دو افست بر حسب گوشه سمت چپ بالای شبکه و ارتفاع و عرض شبکه. جعبه پیش بینی شده
با این رویکرد، پارامترهای شبکه و GFLOPهای آشکارساز کاهش مییابد و باعث میشود که آشکارساز سریعتر شود و نه تنها عملکرد آن تا 42.9% AP بهبود یابد، همانطور که در جدول 8 نشان داده شده است.
چند مثبت
برای سازگاری با قانون تخصیص YOLOv3، نسخه بدون لنگر تنها یک نمونه مثبت (محل مرکز) را برای هر شی انتخاب می کند در حالی که سایر پیش بینی های با کیفیت بالا را نادیده می گیرد. با این حال، بهینهسازی آن پیشبینیهای با کیفیت بالا ممکن است شیبهای مفیدی را نیز به همراه داشته باشد، که ممکن است عدم تعادل شدید نمونهگیری مثبت/منفی را در طول آموزش کاهش دهد. در YOLOX، ناحیه مرکز 3×3 بهعنوان موارد مثبت اختصاص داده میشود که در مقاله FCOS «نمونهگیری مرکزی» نیز نامیده میشود . در نتیجه، عملکرد آشکارساز به 45.0% AP بهبود می یابد، همانطور که در جدول 2 نشان داده شده است.
ستون فقرات دیگر
CSPNet اصلاح شده در YOLOv5
برای مقایسه منصفانه، YOLOX جایگزین ستون فقرات Darknet-53 با ستون فقرات CSP v5 اصلاح شده YOLOv5 همراه با فعال سازی SiLU و سر PAN می شود. با استفاده از قانون پوستهگذاری آن، مدلهای YOLOX-S، YOLOX-M، YOLOX-L و YOLOX-X تولید میشوند.
جدول 9 مقایسه ای بین مدل های YOLOv5 و مدل های تولید شده YOLOX را نشان می دهد. همه انواع YOLOX بهبود ثابتی را بین 3.0٪ تا 1.0٪ AP نشان می دهند، با تنها افزایش زمان نهایی ناشی از استفاده از سر جدا شده. مدل های زیر با وضوح تصویر 640×640، با دقت FP16 (نیمه دقت) و اندازه دسته ای = 1 بر روی یک پردازنده گرافیکی Tesla Volta 100 آزمایش شدند.
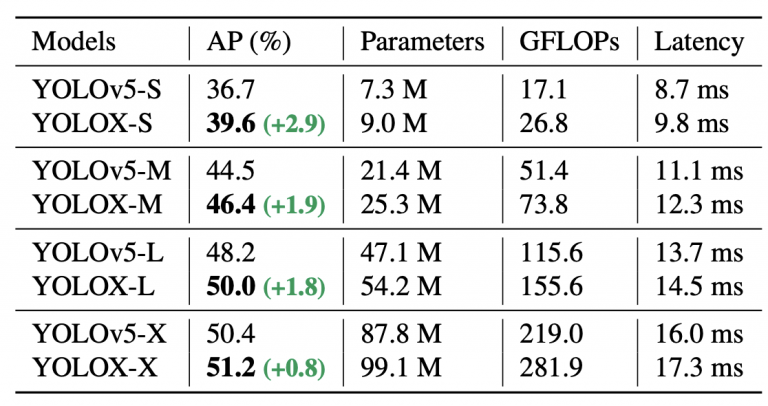
جدول 9: مقایسه انواع YOLOX تولید شده با انواع YOLOv5 موجود از نظر AP (%) در مجموعه داده MS COCO همراه با پارامترها، GFLOP ها و عوامل تاخیر.
آشکارسازهای کوچک و نانو
ما مدلهای YOLOX را با YOLOv5 مقایسه کردیم که از نظر اندازه کوچک، متوسط، بزرگ و فوقالعاده بزرگ بودند (پارامترهای بیشتر). نویسندگان یک گام فراتر رفتند و مدلهای YOLOX را کوچکتر کردند تا پارامترهای کمتری نسبت به نوع YOLOX-S داشته باشند تا YOLOX-Tiny و YOLOX-Nano را تولید کنند. YOLOX-Nano به ویژه برای دستگاه های تلفن همراه طراحی شده است. برای ساخت این مدل، انحراف عمقی اتخاذ شد، که منجر به مدلی با تنها 0.91M پارامتر و 1.08G FLOP شد.
همانطور که در جدول 10 نشان داده شده است ، YOLOX-Tiny با YOLOv4-Tiny و PPYOLO-Tiny مقایسه شده است. باز هم، YOLOX با اندازه مدل حتی کوچکتر از همتایان خود عملکرد خوبی دارد.
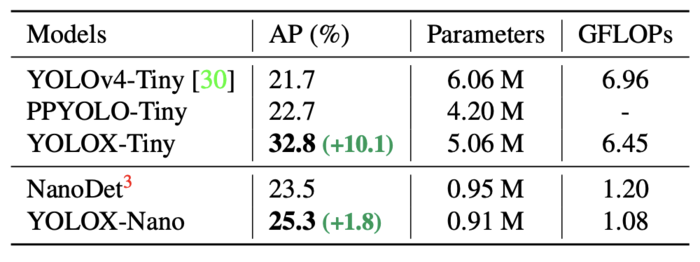
جدول 10: مقایسه YOLOX-Tiny و YOLOX-Nano و همتایان از نظر AP (%) در مجموعه داده اعتبارسنجی MS COCO.
خلاصه
تبریک میگم بابت رسیدن به این مرحله. اگر توانستید به راحتی یا حتی با کمی تلاش بیشتر دنبال کنید، آفرین! پس بیایید به سرعت خلاصه کنیم:
- ما آموزش را با معرفی تشخیص اشیا شروع کردیم: تشخیص اشیاء چگونه با طبقه بندی تصویر متفاوت است، چالش های موجود در تشخیص و آشکارسازهای شی تک مرحله ای و دو مرحله ای چیست.
- سپس با اولین آشکارساز تک مرحله ای به نام YOLOv1 آشنا شدیم.
- سپس به طور خلاصه به YOLOv2، YOLOv3 و YOLOv4 پرداختیم.
- در مرحله بعد، YOLOv5 توسعه یافته توسط Ultralytics، اولین مدل YOLO که پس از YOLOv4 در PyTorch پیاده سازی شد را مورد بحث قرار دادیم.
- سپس PP-YOLO در چارچوب PaddlePaddle توسط Baidu پیادهسازی شد که نتایج امیدوارکنندهای را نشان داد که بهتر از YOLOv4 و EfficientDet بود.
- سپس توسعهای از YOLOv4 به نام Scaled-YOLOv4 مورد بحث قرار گرفت، که بر اساس رویکرد مقطعی جزئی مقیاسبندی هر دو بالا و پایین، شکست دادن معیارهای قبلی از مدلهای تشخیص اشیاء کوچک و بزرگ قبلی مانند EfficientDet، YOLOv4 و PP-YOLO در هر دو سرعت و دقت.
- سپس نسخه دوم PP-YOLO، معروف به PP-YOLOv2 را مورد بحث قرار دادیم، که اصلاحات مختلفی را در PP-YOLO انجام داد و در نتیجه عملکرد (یعنی از 45.9٪ mAP به 49.5٪ mAP) را در مجموعه تست MS COCO2017 به طور قابل توجهی بهبود بخشید.
- سپس YOLOX را مورد بحث قرار دادیم، یک شبکه تشخیص شی بدون Anchor پس از YOLOv1. YOLOX مقام اول را در چالش ادراک جریان در کارگاه CVPR کسب کرد و از مدل های بزرگ و نانو YOLOv5 هم از نظر دقت و هم سرعت بهتر عمل کرد.
منابع
https://blog.roboflow.com/scaled-yolov4-tops-efficientdet/
https://pyimagesearch.com/2022/04/04/introduction-to-the-yolo-family/




دیدگاهتان را بنویسید