
آموزش کتابخانه پانداس (pandas) در پایتون

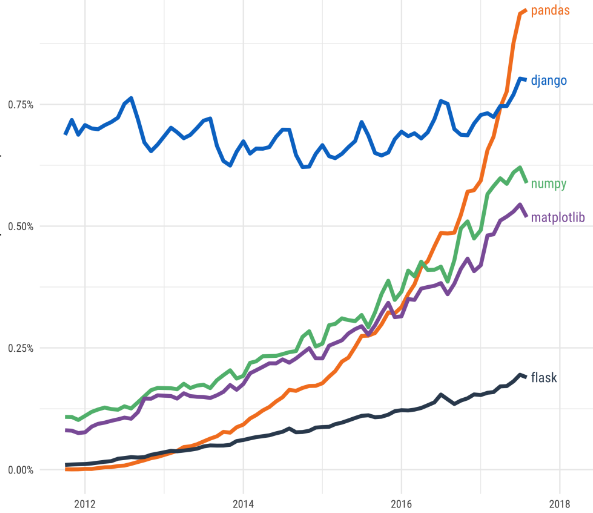
دستکاری و پیش پردازش داده ها با کمک پانداس
پانداس امکان تجزیه و تحلیل، دستکاری، پیش پردازش و مدیریت داده ها را با استفاده از دو ابزار سری ها (سری یک آرایه تک بعدی است که انواع داده های رشته ای، عددصحیح، و اعداد اعشاری را در خود ذخیره می کند) و DataFrame (آرایه ای دو بعدی شامل سطر ها و ستون ها ) را که ساختار های اصلی برای ذخیره داده ها می باشند را فراهم می سازد.
با اینکه Series و DataFrames مباحث بسیار مهمی هستند اما در عین حال هیچ پیچیدگی خاصی ندارند و بسیار ساده هستند! هر series یک ستون ساده است و هر DataFrame یک جدول است که یعنی مجموعه ای از series ها می باشد.
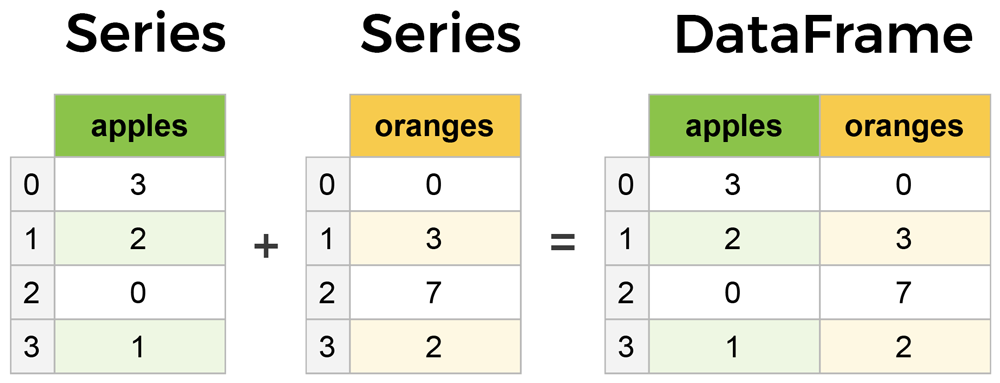
تفاوت series ها و data frame ها در کتابخانه pandas
Series در پانداس
سری ها قادرند انواع داده ها را در خود ذخیره کنند و شامل یک ستون برای اندیس گذاری و ستون یا ستون هایی برای ذخیره مقادیرمی باشند. درصورتی که اندیس گذاری را از قبل مشخص نکنیم به صورت پیش فرض با عدد صفر شروع می شود اما می توانیم آن را با کاراکتر ها نیز نمایش دهیم با کمک اندیس گذاری می توانیم به یک مقدار مشخص دسترسی پیدا کنیم

ساخت یک سری ساده با کمک متد pd.Series
- یک لیست ساخته ایم
- دیتا فریم خود را با استفاده از لیست ایجاد کردیم
- df را صدا زدیم تا خروجی را ببینیم
خروجی👇

دیکشنری خود را ایجاد کردیم
تبدیل آن به دیتا فریم
- df را صدا زدیم تا خروجی را ببینیم
خروجی👇
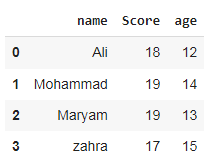
خروجی👇




دیدگاهتان را بنویسید